{kind=link}
{kind=link}
{kind=link}
{kind=link}
Premium File
50 Q&A
€76.99€69.99
Microsoft MCSE 70-466 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate
50 Questions & Answers
Last Update: Oct 20, 2025
€69.99
Microsoft MCSE 70-466 Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File Microsoft.Braindumps.70-466.v2015-04-03.by.Lonnie.173q.vce |
Votes 34 |
Size 4.82 MB |
Date Apr 03, 2015 |
File Microsoft.Actualanswers.70-466.vv2014-10-15.by.MINTA.35q.vce |
Votes 9 |
Size 128.08 KB |
Date Oct 15, 2014 |
File Microsoft.Testking.70-466.v2013-09-19.by.max.94q.vce |
Votes 39 |
Size 1.82 MB |
Date Sep 20, 2013 |
Archived VCE files
| File | Votes | Size | Date |
|---|---|---|---|
File Microsoft.Actualanswers.70-466.v2014-08-20.by.VICKIE.35q.vce |
Votes 3 |
Size 128.09 KB |
Date Aug 20, 2014 |
File Microsoft.Passguide.70-466.v2014-03-29.by.JUDITH.50q.vce |
Votes 1 |
Size 154.82 KB |
Date Mar 29, 2014 |
File Microsoft.PassGuide.70-466.v2014-03-03.by.David.50q.vce |
Votes 2 |
Size 154.82 KB |
Date Mar 04, 2014 |
File Microsoft.Testking.70-466.v2013-07-23.by.DrNo.40q.vce |
Votes 1 |
Size 9.21 MB |
Date Jul 29, 2013 |
Microsoft MCSE 70-466 Practice Test Questions, Exam Dumps
Microsoft 70-466 (Implementing Data Models and Reports with Microsoft SQL Server 2012) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. Microsoft 70-466 Implementing Data Models and Reports with Microsoft SQL Server 2012 exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the Microsoft MCSE 70-466 certification exam dumps & Microsoft MCSE 70-466 practice test questions in vce format.
The Microsoft 70-466 exam, formally titled "Implementing Data Models and Reports with Microsoft SQL Server," was a pivotal certification for professionals specializing in business intelligence and data analytics. It served as a key component of the MCSA: SQL Server 2012/2014 certification, validating a candidate's ability to design and implement robust data models and create insightful reports. While the exam itself has been retired by Microsoft, the core skills it assessed remain fundamental to the modern data landscape. Understanding the concepts tested in the 70-466 exam provides a strong foundation for working with current technologies like Power BI, Azure Analysis Services, and modern data warehousing solutions.
This series will delve into the topics covered in the 70-466 exam, treating it as a structured curriculum for mastering essential BI skills. We will explore the architecture of data warehouses, the intricacies of creating multidimensional and tabular data models using SQL Server Analysis Services (SSAS), and the art of developing compelling reports with SQL Server Reporting Services (SSRS). The knowledge gained from this exploration is timeless, equipping you with the principles needed to transform raw data into actionable intelligence, a skill that is more in demand today than ever before. This journey is not just about a retired exam; it is about building a career in data.
The 70-466 exam was meticulously designed to cover the end-to-end process of BI development within the Microsoft ecosystem. Its primary objective was to ensure a candidate could build a BI solution starting from a data warehouse foundation. This involved creating an analytical layer with SSAS that would serve as a single source of truth for business users. This layer needed to be both powerful and easy to navigate, allowing for complex queries and aggregations to be performed efficiently. The exam tested one's ability to choose the right type of model, whether multidimensional or tabular, based on specific business requirements.
Furthermore, the exam heavily emphasized the consumption layer, which is where the value of the data model is realized. Candidates were required to demonstrate proficiency in SSRS to build a variety of reports, from simple paginated lists to complex, interactive dashboards with parameters and drill-down capabilities. The scope included designing report layouts, creating data connections, writing queries to fetch data, and deploying the reports to a server for consumption. Essentially, passing the 70-466 exam signified that you could not only model data effectively but also present it in a clear, meaningful way to drive business decisions.
A foundational concept for the 70-466 exam is the distinction between Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) systems. OLTP systems are the backbone of day-to-day business operations. Think of an e-commerce order entry system, a bank's transaction system, or a retail point-of-sale terminal. These systems are optimized for a high volume of short, fast transactions like inserts, updates, and deletes. Their database schemas are highly normalized to ensure data integrity and avoid redundancy, often involving many tables joined together. The primary goal of an OLTP system is to record transactions accurately and quickly.
OLAP systems, on the other hand, are designed for analysis and reporting. They are the core of the BI solutions that the 70-466 exam focuses on. Instead of processing thousands of small transactions per second, OLAP systems are optimized to handle a smaller number of very complex queries across large volumes of historical data. For example, a query might be "What were the total sales for each product category in the European region for the last five years, compared to the same period previously?" These systems use denormalized schemas, like star or snowflake schemas, to facilitate fast slicing, dicing, and aggregation of data, making them ideal for the data models built in SSAS.
The data warehouse is the central repository of integrated data from one or more disparate sources, and it serves as the foundation for any BI project covered by the 70-466 exam. Its primary purpose is to store historical data in a way that is optimized for querying and analysis. Unlike an operational database, a data warehouse is not typically updated in real-time. Instead, it is loaded periodically, often nightly, through a process known as ETL (Extract, Transform, Load). During this process, data is extracted from various source systems, transformed into a consistent format, and loaded into the warehouse.
A well-designed data warehouse is subject-oriented, meaning it is organized around the major subjects of the business, such as customers, products, sales, and inventory. It is integrated, ensuring that data from different sources is consistent. It is time-variant, as it stores data over long periods, allowing for trend analysis. Finally, it is non-volatile, meaning that once data is loaded, it is generally not removed or updated; it becomes a permanent historical record. Understanding these characteristics is crucial for building the SSAS models that sit on top of the data warehouse, as the structure of the warehouse directly influences the design of the analytical model.
The star schema is the simplest and most common type of data warehouse schema, and it was a critical topic for the 70-466 exam. It is called a star schema because its structure resembles a star, with a central table connected to several other tables. The table at the center is called the fact table. The fact table contains the quantitative or numerical data for analysis, which are known as measures. Examples of measures include sales amount, quantity sold, or profit margin. It also contains foreign keys that link to the surrounding tables. The primary key of a fact table is usually a composite key made up of these foreign keys.
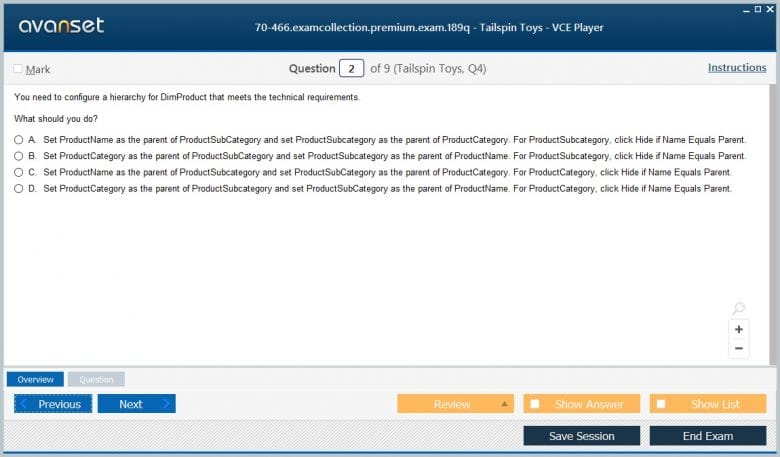
The tables surrounding the fact table are called dimension tables. Each dimension table represents a business entity and contains descriptive attributes that provide context to the measures in the fact table. For instance, you might have a 'DimProduct' dimension with attributes like product name, category, and color. You could also have a 'DimDate' dimension with attributes like year, quarter, and month, and a 'DimCustomer' dimension with customer name and location. Queries using a star schema are simple because they typically require joining the fact table to only one or two dimension tables, making them very efficient for OLAP systems.
An alternative to the star schema is the snowflake schema, another important design pattern relevant to the 70-466 exam. The snowflake schema is an extension of the star schema where the dimension tables are normalized. This means that a dimension table might be connected to other dimension tables, creating a more complex, branched structure that resembles a snowflake. For example, in a star schema, the 'DimProduct' dimension might contain product name, subcategory, and category information all in one table.
In a snowflake schema, the 'DimProduct' table might only contain the product name and a foreign key to a 'DimSubcategory' table. The 'DimSubcategory' table would then contain the subcategory name and a foreign key to a 'DimCategory' table. This normalization reduces data redundancy and can save storage space. However, it comes at a cost. Queries against a snowflake schema are more complex, as they require more joins to retrieve the necessary information. This can sometimes lead to slower query performance compared to the simpler, denormalized star schema. The choice between a star and snowflake schema involves a trade-off between storage efficiency and query performance.
The 70-466 exam was centered on the traditional Microsoft Business Intelligence stack, which consists of three core components: SQL Server Integration Services (SSIS), SQL Server Analysis Services (SSAS), and SQL Server Reporting Services (SSRS). Although the exam focused primarily on SSAS and SSRS, understanding the role of SSIS is crucial for a complete picture. SSIS is the ETL tool of the stack. It is used to build data integration and workflow solutions, extracting data from various sources, applying complex transformations, and loading it into a destination, typically a data warehouse.
SSAS is the analytical engine. It is used to create the semantic data models (cubes or tabular models) that sit on top of the data warehouse. This is where you define measures, dimensions, hierarchies, and business logic. SSAS pre-aggregates data, allowing users to query vast amounts of information with lightning-fast response times. It provides a user-friendly layer of abstraction over the complex underlying database schema. This component was a major focus of the 70-466 exam.
Finally, SSRS is the reporting and presentation tool. It connects to the SSAS models (or other data sources) to create, manage, and deliver a wide range of reports. These can be paginated reports ideal for printing, interactive reports for on-screen analysis, or mobile reports for on-the-go access. SSRS provides the final output for the end-user, visualizing the data processed by SSIS and modeled by SSAS. Mastering SSAS and SSRS was the key to success on the 70-466 exam.
Embarking on the path to mastering the skills from the 70-466 exam requires a structured approach. The first step is to build a solid theoretical foundation in data warehousing principles. This includes a deep understanding of dimensional modeling, fact and dimension tables, and schema design. It is impossible to build a good analytical model without a well-designed data warehouse underneath it. This foundational knowledge will inform every decision you make when designing cubes or tabular models in SSAS.
Once the theory is in place, practical, hands-on experience becomes paramount. Setting up a development environment with SQL Server and the BI development tools is essential. You can start with sample databases like AdventureWorksDW, which was commonly used for practice scenarios related to the 70-466 exam. Walking through tutorials to build a simple star schema, then an SSAS cube on top of it, and finally a basic SSRS report that consumes data from that cube, is a great way to connect the dots between the different components.
This initial phase is about understanding the "why" behind the "how." Why do we denormalize dimensions in a star schema? Why are pre-calculated aggregations in SSAS so much faster than running queries directly against the data warehouse? Answering these questions builds the intuition needed to tackle more complex, real-world scenarios. The subsequent parts of this series will dive deeper into the specific technologies, starting with the powerful multidimensional models in SSAS, providing the detailed knowledge required to master these enduring BI concepts.
Building upon the foundational concepts of data warehousing, this part of the series focuses on a core component of the 70-466 exam: SQL Server Analysis Services (SSAS) Multidimensional Models. For many years, multidimensional modeling was the cornerstone of enterprise business intelligence solutions built on the Microsoft platform. This technology allows for the creation of OLAP cubes, which are highly optimized data structures designed for rapid data analysis. A cube provides a powerful and intuitive way for users to slice, dice, pivot, and drill down into vast amounts of data, uncovering trends and insights that would be difficult to find using traditional relational databases.
Mastering SSAS Multidimensional models requires understanding a unique set of concepts, including dimensions, attributes, hierarchies, measures, and the query language used to interact with them, Multidimensional Expressions (MDX). The 70-466 exam required candidates to not only build these cubes from scratch but also to enhance them with business logic, calculations, and performance optimizations. Even with the rise of newer technologies like tabular models, the principles of multidimensional analysis remain incredibly relevant, and the skills learned here are transferable to many modern analytics platforms. This section will provide a detailed exploration of creating and managing these powerful analytical tools.
At the heart of an SSAS Multidimensional model is the OLAP cube. A cube is not a physical three-dimensional structure but a conceptual way of organizing data. It is defined by its measures and dimensions. Measures are the numerical values that users want to analyze, such as Sales Amount, Order Quantity, or Unit Price. These are typically derived from the columns in a fact table in your data warehouse. Dimensions provide the context for the measures. They are the "by which" you analyze the data, for example, analyzing Sales Amount "by" Time, "by" Product, or "by" Geography.
The power of a cube lies in its ability to store pre-aggregated data. When the cube is processed, SSAS calculates and stores the values of measures at various levels of the dimensional hierarchies. For instance, it might pre-calculate total sales for each day, month, quarter, and year. When a user queries for sales in a specific quarter, the answer can be retrieved almost instantly from these pre-calculated aggregations rather than having to scan and sum millions of rows in the underlying fact table. This is what provides the incredible speed associated with OLAP analysis and was a key performance concept tested in the 70-466 exam.
Dimensions are the descriptive, contextual elements of a cube and are a fundamental building block you needed to master for the 70-466 exam. Each dimension is built from one or more tables in the underlying data source, typically a dimension table from a star schema. Within each dimension are attributes, which are the individual columns that describe the dimension. For example, a Product dimension might have attributes like Product Name, Color, Size, Subcategory, and Category. These attributes are what users will use to slice and filter the data in the cube.
When creating a dimension in SQL Server Data Tools (the development environment for SSAS), you define the attributes and, crucially, the relationships between them. For instance, you would define that many Products belong to one Subcategory, and many Subcategories belong to one Category. These are called attribute relationships. Defining these relationships correctly is critical for both query performance and the correct functioning of user-defined hierarchies. An incorrectly defined relationship can lead to incorrect data aggregation and slow query execution, highlighting the importance of careful design.
While users can analyze data by dragging and dropping individual attributes, a more intuitive way to explore the data is through hierarchies. A user-defined hierarchy is a logical, tree-like structure of attributes arranged into levels. For example, in a Geography dimension, you could create a hierarchy called 'Geographical Location' with levels for Country, State, and City. This allows a user to start by looking at sales by Country, then drill down to see the breakdown by State within a specific country, and then further down to the City level.
These hierarchies provide a natural path for navigation and analysis. For the 70-466 exam, you needed to know how to create different types of hierarchies. Natural hierarchies, like the geography example, follow a one-to-many relationship between levels (one country has many states). Unnatural hierarchies might group attributes that do not have a direct hierarchical relationship, such as creating a 'Product Demographics' hierarchy with levels for Color and Size. Correctly implementing hierarchies is key to creating a user-friendly and powerful analytical model, as it guides the end-user through their data exploration journey.
Measures represent the core numerical data that a business wishes to track and analyze. In an SSAS cube, measures are organized into measure groups. A measure group typically corresponds to a fact table in the data warehouse. For instance, if you have a 'FactInternetSales' table, you would create an 'Internet Sales' measure group in your cube. This measure group would contain measures like 'Order Quantity', 'Sales Amount', and 'Total Product Cost', which are derived from the columns in that fact table.
When defining a measure, you must specify its aggregation function. The most common function is 'Sum', but others like 'Count', 'Min', 'Max', and 'Average' are also frequently used. The 70-466 exam required an understanding of different aggregation behaviors. For example, some measures, like an inventory balance, are not additive across time. You cannot sum the inventory balance for each day of the month to get the monthly balance. This is known as a semi-additive measure, and you would need to configure its aggregation behavior correctly (e.g., 'LastNonEmpty') to ensure accurate reporting.
To query an SSAS Multidimensional cube, you use Multidimensional Expressions, or MDX. MDX is to cubes what SQL is to relational databases. However, it is fundamentally different in its concepts and syntax. Instead of thinking in terms of tables, rows, and columns, MDX thinks in terms of dimensions, hierarchies, levels, and members. An MDX query is used to define a result set, specifying which members from which dimensions should appear on the rows and columns, and which measure values should appear in the cells.
A basic MDX query has a SELECT clause that defines the axes (e.g., COLUMNS and ROWS) and a FROM clause that specifies the cube. A WHERE clause can be used to slice the data, filtering the entire cube to a specific context before the axis selections are applied. For example, you could write a query to show Product Sales on the rows and Calendar Years on the columns, all sliced by the region of North America. While end-users often interact with cubes through graphical tools like Excel PivotTables that generate MDX behind the scenes, a developer preparing for the 70-466 exam needed a solid understanding of MDX to create advanced calculations and troubleshoot queries.
Key Performance Indicators (KPIs) are a critical part of any business intelligence solution, as they provide a quick visual representation of how a business is performing against its goals. SSAS Multidimensional models have built-in support for creating KPIs. A KPI is a collection of calculations that includes a value, a goal, a status, and a trend. For example, a sales KPI might have a 'Value' of the current month's sales, a 'Goal' of the budgeted sales for the month, a 'Status' that shows a red, yellow, or green indicator based on how the value compares to the goal, and a 'Trend' that shows whether performance is improving or declining over time.
Each part of the KPI is defined using an MDX expression. The 'Value' might be a simple measure, while the 'Goal' could be a value from another measure group or a static number. The 'Status' and 'Trend' are typically defined with CASE statements in MDX, which return a value (e.g., -1 for bad, 0 for neutral, 1 for good) that client tools can interpret to display a graphical indicator. The ability to define and implement KPIs directly within the cube was a key skill tested in the 70-466 exam, as it centralizes business logic and ensures consistent performance measurement across all reports and dashboards.
One of the most powerful features of SSAS is the ability to extend the cube's capabilities with custom calculations using MDX. Instead of just analyzing the base measures from the fact table, you can create new calculated measures that provide deeper business insight. A common example is 'Profit Margin', which could be calculated as ([Measures].[Sales Amount] - [Measures].[Total Product Cost]) / [Measures].[Sales Amount]. This calculation is defined once in the cube and is then available to all users as if it were a regular measure.
You can also create calculated members on dimensions. For instance, on a Time dimension, you could create a calculated member called 'Year-over-Year Growth' that dynamically calculates the percentage change in sales compared to the previous year. Another useful feature is named sets. A named set is a pre-defined set of dimension members that can be used in queries. For example, you could create a named set called 'Top 10 Products' that dynamically returns the ten products with the highest sales. The 70-466 exam required proficiency in creating these MDX-based enhancements to deliver significant value beyond the raw data.
While multidimensional models represented the traditional approach to BI in the Microsoft stack, the 70-466 exam also covered its modern counterpart: SQL Server Analysis Services (SSAS) Tabular Models. Introduced with SQL Server 2012, the tabular model offers a different, often simpler, approach to data modeling based on relational concepts like tables and relationships. It is built upon the xVelocity in-memory analytics engine (formerly known as VertiPaq), which provides phenomenal performance through state-of-the-art compression and column-store technology. This allows tabular models to store vast amounts of data in memory and deliver query results with incredible speed.
For many developers, especially those coming from a relational database background, the tabular model is more intuitive than the multidimensional cube. Its query language, Data Analysis Expressions (DAX), shares syntactical similarities with Excel formulas, making it more accessible to a broader audience of power users and analysts. The 70-466 exam required a thorough understanding of both modeling approaches, testing a candidate's ability to choose the right model for a given scenario and to build, enhance, and query tabular models effectively. This section will explore the architecture, development, and querying of these powerful in-memory data models.
The foundation of the SSAS Tabular model is the xVelocity in-memory analytics engine. Unlike multidimensional models that use MOLAP storage on disk with pre-aggregated data, tabular models primarily operate by loading the entire dataset into RAM. This in-memory approach is a key reason for its speed. When a query is executed, it runs against the data held in memory, eliminating the latency associated with disk reads. This makes it exceptionally fast for a wide range of analytical queries, especially those involving scans and aggregations over large tables.
The engine employs advanced algorithms to achieve high levels of data compression. It uses column-store storage, which means that instead of storing data row by row, it stores data column by column. This is highly efficient for analytical workloads because queries typically only need to access a few columns from a table, not all of them. The column-store structure allows the engine to only read the necessary columns from memory. Furthermore, because data within a single column often has low cardinality (fewer unique values), it can be compressed very effectively, allowing more data to fit into the available RAM. Understanding these principles was key for capacity planning and performance tuning, topics relevant to the 70-466 exam.
Developing a tabular model feels much like working with a relational database. The process begins by importing tables from one or more data sources. During the import process, you can select specific tables and columns, filter rows, and rename objects to create a more user-friendly model. Once the tables are imported into the model, they exist as objects within the tabular database. The next crucial step is to define the relationships between these tables.
Relationships in a tabular model work just like they do in a relational database, defining how tables are connected based on a common column, typically a primary key in one table and a foreign key in another. For example, you would create a relationship between a 'Sales' table and a 'Product' table on the 'ProductKey' column. These relationships are essential for enabling data exploration and ensuring that calculations correctly propagate filters across the model. The 70-466 exam required candidates to be proficient in creating and managing these relationships, including handling more complex scenarios like many-to-many relationships or inactive relationships.
Just as MDX is the query language for multidimensional models, Data Analysis Expressions (DAX) is the formula and query language for tabular models (and for Power BI). DAX is used to create calculated columns, measures, and tables, allowing you to add powerful business logic to your model. While DAX has a syntax that resembles Excel formulas, it is a far more powerful language that operates on entire tables and columns rather than individual cells. It is a functional language, where every expression is a function call.
A key concept in DAX is the evaluation context, which consists of row context and filter context. Row context refers to iterating through the rows of a table, typically when creating a calculated column. Filter context is the set of active filters applied to the data model, which comes from user selections in a report or from other calculations. Mastering how to manipulate the filter context using functions like CALCULATE, FILTER, ALL, and RELATED is the most critical skill for any DAX developer and was a major focus for anyone preparing for the 70-466 exam.
One of the most important distinctions to understand when working with DAX is the difference between a calculated column and a measure. A calculated column is an extension of a table. You write a DAX formula that is evaluated for each row of the table during data processing (or refresh), and the result is stored in the model just like any other column. This consumes memory and increases the model size. Calculated columns are useful when you want to create a new attribute that you can use to slice or filter data, such as creating a 'Price Category' column (e.g., 'Low', 'Medium', 'High') based on a product's unit price.
A measure, on the other hand, is a formula that is evaluated at query time. It is not stored in the model and therefore does not consume memory in the same way. Measures are designed for aggregation and are evaluated within the filter context of a report visual. For example, a 'Total Sales' measure would be defined as SUM(Sales[SalesAmount]). When a user puts this measure in a chart showing sales by year, the DAX engine calculates the sum of sales for each year separately. The 70-466 exam required a deep understanding of when to use a calculated column versus a measure, as making the wrong choice can have significant performance implications.
To be successful with the 70-466 exam, you needed to be proficient with a core set of DAX functions. The most important function in all of DAX is CALCULATE. It allows you to modify the filter context in which an expression is evaluated. For example, you could calculate the sales for a specific region, regardless of the user's current filter selection, using a formula like CALCULATE([Total Sales], 'Geography'[Region] = "Europe"). This ability to manipulate filters is the foundation of complex analytics.
Other critical functions include iterators like SUMX and AVERAGEX, which perform a calculation for each row in a table and then aggregate the result. Time intelligence functions are also essential. DAX provides a rich library of functions like TOTALYTD (year-to-date), SAMEPERIODLASTYEAR, and DATEADD that simplify the process of performing time-based comparisons, a common requirement in business reporting. Relational functions like RELATED and RELATEDTABLE are used to navigate relationships and retrieve values from other tables. A solid grasp of these function categories was non-negotiable for the exam.
Similar to multidimensional models, tabular models also support the creation of hierarchies to facilitate user navigation and drill-down analysis. In a tabular model, creating a hierarchy is a straightforward process. You simply drag and drop the desired columns from a table into a hierarchy structure in the model's diagram view. For example, in a 'Date' table, you could create a 'Calendar' hierarchy consisting of 'CalendarYear', 'CalendarQuarter', 'MonthName', and 'Day' columns. These hierarchies then appear as single, expandable objects in client tools.
Tabular models also support Key Performance Indicators (KPIs). A KPI in a tabular model is based on a measure. You select a base measure (the Value), then define another measure or an absolute value as the Target (the Goal). Finally, you define the thresholds for the Status, which determines the graphical indicator. For instance, if the value is less than 80% of the target, the status is 'Bad'; if it's between 80% and 100%, it's 'Neutral'; and if it's over 100%, it's 'Good'. This provides a simple yet effective way to embed performance metrics directly into the data model for consistent reporting.
A key decision for a BI architect, and a conceptual topic for the 70-466 exam, is choosing between a multidimensional and a tabular model. The choice depends on several factors, including the complexity of the business logic, the size of the data, and the skill set of the development team. Tabular models are generally faster to develop and easier to learn, especially for those with a SQL background. They excel at handling large datasets and performing simple aggregations very quickly due to the in-memory engine.
Multidimensional models, however, offer more advanced and complex analytical capabilities. They support many-to-many relationships more natively, have robust support for parent-child hierarchies (like organizational charts), and allow for more complex calculations and scoping using MDX. While tabular models have closed the gap over the years, there are still some complex analytical scenarios where a multidimensional cube is the superior choice. A well-rounded BI professional, as validated by the 70-466 exam, should be able to analyze the requirements of a project and recommend the appropriate modeling technology.
Mastering SQL Server Reporting Services (SSRS)
After building a robust analytical data model in SSAS, the next logical step in any business intelligence solution is to present the data to end-users. This is the domain of SQL Server Reporting Services (SSRS), the second major technology pillar of the 70-466 exam. SSRS is a comprehensive, server-based reporting platform that allows you to create, manage, and deliver a wide variety of interactive and printed reports. It provides a complete set of tools for designing reports, connecting to data sources, and rendering reports in various formats, such as HTML for web viewing, PDF for printing, and Excel for further analysis.
Proficiency in SSRS was non-negotiable for passing the 70-466 exam. Candidates were expected to demonstrate the ability to design complex report layouts, write queries to retrieve data from both relational and analytical sources like SSAS cubes, implement interactivity through parameters and actions, and manage the report deployment and security lifecycle. While newer tools like Power BI have gained popularity for interactive dashboards, SSRS remains a powerful and widely used tool for enterprise-level, paginated reporting—the kind of pixel-perfect reports that are often required for official statements, invoices, and operational summaries.
Understanding the architecture of SSRS is fundamental. The platform consists of several key components. The Report Server is the core engine that manages the processing and rendering of reports. It hosts a web service for report management and access. The Report Server database is a SQL Server database that stores all report definitions, metadata, security settings, and subscription information. The Report Manager was a web-based application used to administer the report server, manage content, and set security. In later versions, this was integrated into a web portal.
For development, the primary tool is SQL Server Data Tools (SSDT), which integrates into Visual Studio. This is where developers design their reports in a project-based environment. A report definition is an XML file with an .rdl (Report Definition Language) extension. This file contains everything about the report: the data sources, the datasets (queries), the layout of the report items, and any expressions or custom code. When a user requests a report, the Report Server processes the RDL file, executes the queries, combines the data with the layout, and renders the final report in the requested format. This architecture was central to the deployment and management topics of the 70-466 exam.
Every report begins with data. In SSRS, the first step is to define a data source, which is essentially a connection string to where your data lives. SSRS can connect to a wide array of data sources, including SQL Server relational databases, Oracle, and, most importantly for the 70-466 exam, SQL Server Analysis Services models (both multidimensional and tabular). A data source can be embedded within a single report, or it can be a shared data source, which can be created once and used by multiple reports, making maintenance much easier.
Once a data source is defined, you create one or more datasets. A dataset contains a query that specifies what data to retrieve from the data source. If you are connecting to a relational source, the query will be written in SQL. If you are connecting to an SSAS multidimensional cube, the query will be written in MDX. If connecting to an SSAS tabular model, you will use DAX. The 70-466 exam required the ability to write these queries, often using a graphical query designer but also understanding the underlying language. The fields returned by the query become available to use in the report layout.
The core of report design in SSRS revolves around data regions, which are controls that display data from a dataset. The most versatile data region is the Tablix, which is a combination of a table, a matrix (crosstab or pivot table), and a list. A table displays data in a simple row-and-column format with static columns. A matrix has dynamic columns and rows, allowing you to group data both vertically and horizontally, which is perfect for summarizing data from an OLAP cube. A list provides a free-form layout where you can arrange report items for each record.
Beyond the Tablix, SSRS provides a rich set of data visualizations. You can create various chart types, including bar, column, line, pie, and scatter charts, to graphically represent your data. Gauges and indicators are useful for displaying Key Performance Indicators (KPIs), showing a single value against a scale or goal. Maps can be used to visualize geographical data. A significant part of the 70-466 exam was focused on choosing the right visualization for the data and configuring its properties, such as colors, labels, and axes, to create a clear and effective report.
Static reports have their uses, but the real power of SSRS comes from creating interactive reports that allow users to customize the data they see. The primary mechanism for this is through parameters. A report parameter is a value that a user can provide when they run the report, which can then be used to filter the data. For example, you could create parameters for 'StartDate' and 'EndDate' to allow a user to select a date range for a sales report. The values of these parameters are then incorporated into the dataset query's WHERE clause or filter expression.
Parameters can be configured in various ways. They can be free-form text boxes, or they can be populated with a list of available values queried from a database (e.g., a dropdown list of product categories). You can create cascading parameters, where the selection in one parameter filters the available choices in another (e.g., selecting a country filters a list of states). Parameters are a fundamental skill for building user-driven reports and were heavily tested on the 70-466 exam, requiring knowledge of how to create them, link them to datasets, and manage their properties.
To add dynamic behavior and custom logic to a report, SSRS uses expressions. Expressions are written in a syntax based on Microsoft Visual Basic and are used throughout the report definition. You can use expressions to format data based on its value (e.g., display negative numbers in red), dynamically control the visibility of report items, calculate new fields, or customize report properties like titles and headers. For instance, you could create a title for a report that includes the value of a parameter selected by the user, such as "Sales Report for the Year: 2024".
For more complex logic that cannot be achieved with simple expressions, SSRS allows you to embed custom Visual Basic code directly into the report definition. You can write functions in this code block and then call them from your expressions. While this should be used sparingly for performance and maintenance reasons, it provides an escape hatch for very complex business requirements. Understanding the scope and syntax of expressions was a key skill needed to solve many of the report design challenges presented in the 70-466 exam.
Creating a report in SSDT is only the first half of the process. Once the report is ready, it must be deployed to the Report Server to make it available to users. Deployment is typically managed at the project level in SSDT. You configure the project properties with the URL of the target Report Server and the folder path where the reports, shared data sources, and shared datasets should be published. With a single click, you can then deploy all the items in your project to the server.
After deployment, the next critical task is to configure security. SSRS uses a role-based security model. You can grant access to folders and individual reports by assigning users and groups to predefined roles like 'Browser' (can view reports), 'Content Manager' (can manage content within a folder), and 'Publisher' (can deploy reports). You can also create custom roles with specific permissions. An administrator needs to carefully manage these permissions to ensure that users can only see the data they are authorized to access. The management and security aspects of the report lifecycle were important topics for the 70-466 exam.
One of the most powerful enterprise features of SSRS is subscriptions. A subscription is a standing request to deliver a report at a specific time or in response to an event. This allows you to automate the distribution of reports, pushing information to users rather than requiring them to pull it from the portal. For example, a sales manager could subscribe to a daily sales summary report and have it delivered to their email inbox as a PDF attachment every morning at 8:00 AM.
SSRS supports two types of subscriptions: standard and data-driven. A standard subscription delivers a single instance of a report to a static list of recipients. A data-driven subscription is more dynamic. It uses a query to generate the list of recipients, report parameters, and delivery options at run time. For instance, you could have a single data-driven subscription that sends each regional manager a sales report filtered for their specific region. Understanding how to configure and manage these subscriptions was a key operational skill assessed by the 70-466 exam.
Having covered the core technologies of SSAS and SSRS, this final part of the series addresses the advanced topics and overarching concepts that were part of the 70-466 exam. This includes implementing robust security models, understanding the basics of data mining, and appreciating the full lifecycle of a data warehouse project. While the exam itself is retired, mastering these areas completes the picture of a skilled BI developer and provides knowledge that is directly transferable to today's data platforms. The principles of securing data, finding patterns, and managing a BI solution remain constant, even as the tools evolve.
Furthermore, it is crucial to place the skills from the 70-466 exam into a modern context. The Microsoft data platform has evolved significantly with the advent of Power BI and Azure cloud services. We will explore how the foundational knowledge of SSAS tabular models provides a direct path to expertise in Power BI data modeling and Azure Analysis Services. Similarly, the skills gained in SSRS for paginated reporting are still in high demand and have a direct equivalent in the cloud. This final discussion will bridge the gap between the classic BI stack and the modern analytics landscape, ensuring the knowledge from this journey remains valuable for years to come.
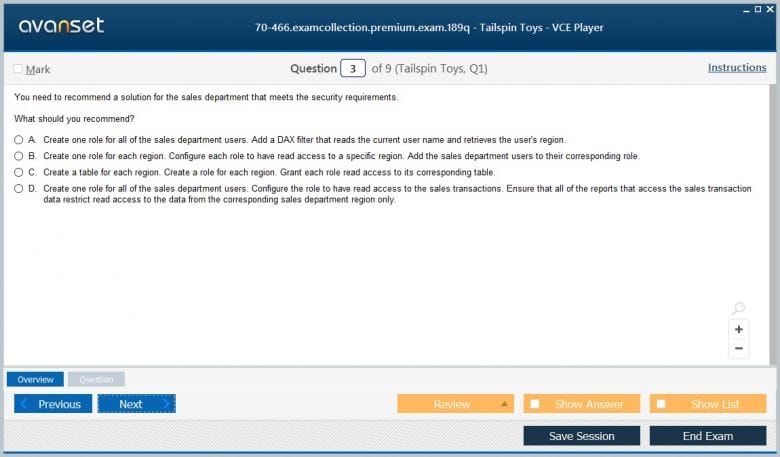
Securing the analytical data model is a critical responsibility for any BI developer, and it was a key topic in the 70-466 exam. SSAS provides a rich, role-based security model for both multidimensional and tabular models. The process starts by creating roles on the server. You then add Windows users or groups to these roles. A user's ability to access or query a cube or tabular model is determined by the permissions of the role they belong to. At a minimum, a role must have read access to the database and the specific model.
Beyond simple access control, SSAS allows for fine-grained, data-level security. For multidimensional models, you can use dimension security to restrict access to specific members of a dimension. For example, you could create a role for the European Sales Manager that only allows them to see data related to European countries. For tabular models, this is achieved through row-level security (RLS). With RLS, you use a DAX expression to define a filter on a table. This DAX filter is automatically applied to every query a user in that role executes, ensuring they only see the rows of data they are permitted to see.
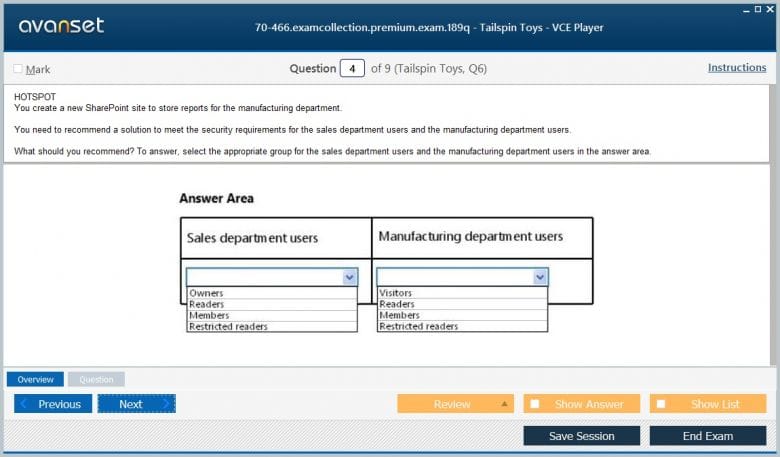
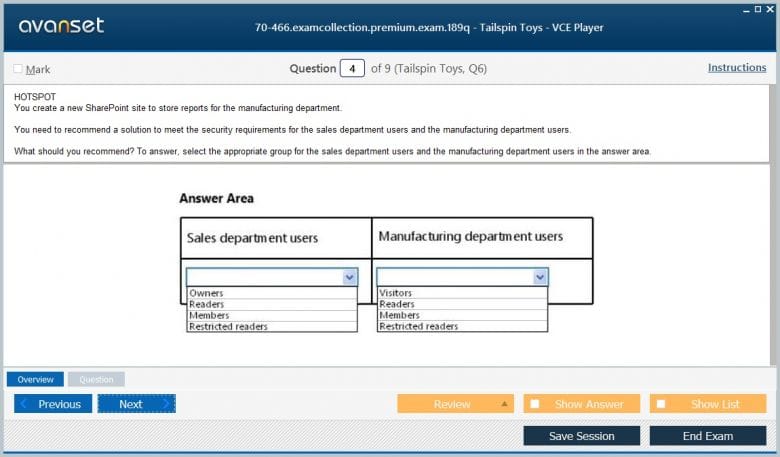
Security in SSRS operates at the report server level and is distinct from the security in the underlying SSAS data source. As mentioned previously, SSRS uses a role-based model to control access to items stored on the server, such as reports, folders, and data sources. This is known as item-level security. It controls who can view, manage, and subscribe to reports. This is the first layer of security, determining whether a user can even run a particular report.
The second layer of security relates to the data itself. When a user runs a report, the report's dataset executes a query against the data source (like an SSAS cube). The permissions for this query depend on how the data source is configured. It can use stored credentials, prompted credentials, or integrated Windows security. If it uses integrated security, the query runs under the security context of the user running the report. This means that the security defined in SSAS (like row-level security) will be enforced, and the user will only see the data they are authorized to see within the report. The 70-466 exam required an understanding of how these two security models interact.
While a smaller part of the 70-466 exam, data mining concepts were included as an advanced analytical capability of SSAS multidimensional models. SSAS provided a suite of data mining algorithms that could be used to discover patterns and relationships in large datasets. This was not about writing queries to answer known questions but about using algorithms to uncover hidden insights. For example, you could use the Microsoft Association Rules algorithm to perform market basket analysis, finding which products are frequently purchased together.
Other available algorithms included Clustering, which could be used to segment customers into distinct groups based on their attributes and behaviors, and Decision Trees, which could help predict an outcome (e.g., whether a customer is likely to churn) based on a set of inputs. A developer would create a mining structure to define the data and then apply one or more mining models to it. While dedicated machine learning platforms are more common for this work today, understanding the basic concepts of applying predictive analytics within a BI solution was a valuable skill.
The 70-466 exam was not just about technical implementation; it also touched upon the broader context of managing a BI solution. This includes understanding the lifecycle of a data warehouse. A typical project involves requirements gathering, dimensional modeling (designing the star schema), developing the ETL processes (using SSIS) to populate the warehouse, building the SSAS analytical models, and finally, creating the SSRS reports for end-users. A developer needs to understand how these pieces fit together.
This also includes ongoing maintenance and operations. Data warehouses need to be processed regularly to load new data. SSAS models need to be processed to update their data and aggregations. Performance needs to be monitored and tuned. This could involve creating aggregations in multidimensional cubes or optimizing DAX queries in tabular models. Understanding how to manage partitions to process large tables more efficiently or how to troubleshoot a slow-running report are practical skills that were conceptually covered by the exam objectives.
The skills you develop for SSAS Tabular models are perhaps the most directly transferable to the modern Microsoft data platform. The engine and concepts behind SSAS Tabular are the very same ones that power Power BI, Microsoft's leading self-service BI and data visualization tool. When you import data into Power BI Desktop, you are creating an in-memory tabular model. The DAX formulas you write for calculated columns and measures are identical. The principles of data modeling, creating relationships, and optimizing performance are exactly the same.
Furthermore, Microsoft offers Azure Analysis Services, which is essentially SSAS Tabular as a platform-as-a-service (PaaS) offering in the Azure cloud. You can develop a tabular model in SSDT or Visual Studio and deploy it to Azure Analysis Services without any changes. This provides a highly scalable, fully managed BI semantic model in the cloud. Therefore, mastering SSAS Tabular as part of the 70-466 exam curriculum effectively makes you an expert in the data modeling component of Power BI and Azure Analysis Services, placing you at the heart of the modern Microsoft BI ecosystem.
While interactive dashboards in tools like Power BI have taken center stage, the need for pixel-perfect, paginated reports has not disappeared. Businesses still require invoices, financial statements, operational reports, and official documents that need to be formatted precisely for printing or sharing as a PDF. The skills learned in SSRS are directly applicable to this ongoing need. Many organizations continue to run SSRS on-premises for their enterprise reporting needs.
Microsoft has also brought this capability to the cloud with Power BI Paginated Reports. This feature, part of Power BI Premium, allows you to create and host SSRS-style .rdl reports within the Power BI service. The development tool for these reports, Power BI Report Builder, is a modern version of the SSRS Report Builder tool and uses the same concepts of data sources, datasets, Tablix controls, and expressions. Therefore, mastering SSRS for the 70-466 exam provides a direct and valuable skill set for producing enterprise-level paginated reports, both on-premises and in the cloud with Power BI.
The journey through the curriculum of the 70-466 exam is a comprehensive education in the principles of business intelligence. Although the specific exam code is retired, the underlying knowledge is more relevant than ever. Understanding how to design a data warehouse, build a semantic model that provides a single source of truth, and create compelling reports are timeless skills in the world of data. The technologies may evolve, but the fundamental concepts of transforming raw data into actionable insight remain the same.
The transition from on-premises SSAS and SSRS to cloud-based services like Azure Analysis Services and Power BI is a natural evolution, not a replacement. The foundational skills in dimensional modeling, DAX, MDX, and paginated report design are the building blocks upon which modern solutions are built. By studying the topics of the 70-466 exam, you are not learning about a legacy product; you are learning the enduring principles of data modeling and reporting that will serve you throughout your career in the ever-expanding field of data analytics
Go to testing centre with ease on our mind when you use Microsoft MCSE 70-466 vce exam dumps, practice test questions and answers. Microsoft 70-466 Implementing Data Models and Reports with Microsoft SQL Server 2012 certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using Microsoft MCSE 70-466 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually
Microsoft 70-466 Video Course
Top Microsoft Certification Exams
Site Search:
SPECIAL OFFER: GET 10% OFF
Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.
Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.