{kind=link}
{kind=link}
{kind=link}
{kind=link}
Premium File
52 Q&A
€76.99€69.99
Microsoft MCSA 70-761 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate
52 Questions & Answers
Last Update: Oct 20, 2025
€69.99
Microsoft MCSA 70-761 Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File Microsoft.Prep4sure.70-761.v2018-09-20.by.Sebastian.75q.vce |
Votes 6 |
Size 8.64 MB |
Date Sep 26, 2018 |
File Microsoft.Dumps.70-761.v2017-01-10.by.Matt.60q.vce |
Votes 19 |
Size 1.24 MB |
Date Jan 13, 2017 |
File Microsoft.Testbells.70-761.v2017-01-05.by.Bob.70q.vce |
Votes 14 |
Size 2.59 MB |
Date Jan 13, 2017 |
Microsoft MCSA 70-761 Practice Test Questions, Exam Dumps
Microsoft 70-761 (Querying Data with Transact-SQL) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. Microsoft 70-761 Querying Data with Transact-SQL exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the Microsoft MCSA 70-761 certification exam dumps & Microsoft MCSA 70-761 practice test questions in vce format.
The 70-761 Exam, known as "Querying Data with Transact-SQL," was a fundamental certification for any professional working with Microsoft SQL Server. It served as one of the two exams required for the MCSA: SQL 2016 Database Development certification. Although this specific exam has been retired as part of Microsoft's shift towards role-based certifications, the skills it validated remain timeless and essential. The ability to write proficient Transact-SQL (T-SQL) code is the bedrock of database development, data analysis, business intelligence, and database administration.
This series will use the curriculum of the 70-761 Exam as a comprehensive roadmap for mastering the T-SQL language. The exam's objectives were meticulously designed to cover the most critical aspects of querying and manipulating data. By following this structure, you can build a robust and practical skill set that is highly valued in the industry, regardless of the availability of the exam itself. We will treat the 70-761 Exam as our structured guide to becoming a skilled T-SQL practitioner.
In this first part, we will focus on the absolute basics, mirroring the initial knowledge domains of the 70-761 Exam. We will begin by understanding the core concepts of relational databases and the structure of T-SQL queries. We will cover how to retrieve data using the SELECT statement, how to filter that data effectively with the WHERE clause, and how to sort and present it in a meaningful way. Finally, we will introduce the concept of joining data from multiple tables, a fundamental skill for working with relational data.
Mastering these foundational elements is the first and most important step on your journey. A solid understanding of how to select, filter, and join data forms the basis for all other advanced querying techniques. The 70-761 Exam rightly placed a heavy emphasis on these fundamentals, as they are the operations that developers and analysts perform every single day. Let's begin building that foundation.
Before diving into T-SQL, it is crucial to understand the structure of the environment you will be working in: the relational database. A relational database organizes data into one or more tables. Each table is a collection of rows and columns. A column, also known as an attribute or field, defines a specific type of data that is stored for each record, such as a customer's name or a product's price. A row, also known as a record or tuple, represents a single entity within the table, such as one specific customer or one specific product.
The power of the relational model comes from the relationships that can be defined between tables. These relationships are established using keys. A primary key is a column (or set of columns) that uniquely identifies each row in a table. For example, a CustomerID column would be a primary key in a Customers table. A foreign key is a column in one table that refers to the primary key of another table. For instance, an Orders table would have a CustomerID column that is a foreign key referencing the Customers table.
This structure allows data to be stored efficiently and without redundancy, a concept known as normalization. Instead of repeating a customer's full name and address for every order they place, we can store the customer information once in the Customers table and simply reference the CustomerID in the Orders table. The 70-761 Exam assumed a strong understanding of this model, as T-SQL is the language used to navigate these relationships and combine data from different tables to answer complex questions.
Transact-SQL, or T-SQL, is Microsoft's dialect of the standard SQL (Structured Query Language). SQL is the declarative language used to communicate with a relational database. With T-SQL, you tell the database what data you want to retrieve, insert, update, or delete, and the database management system (DBMS) figures out the most efficient way to perform the operation. This declarative nature is what makes SQL so powerful and universally adopted.
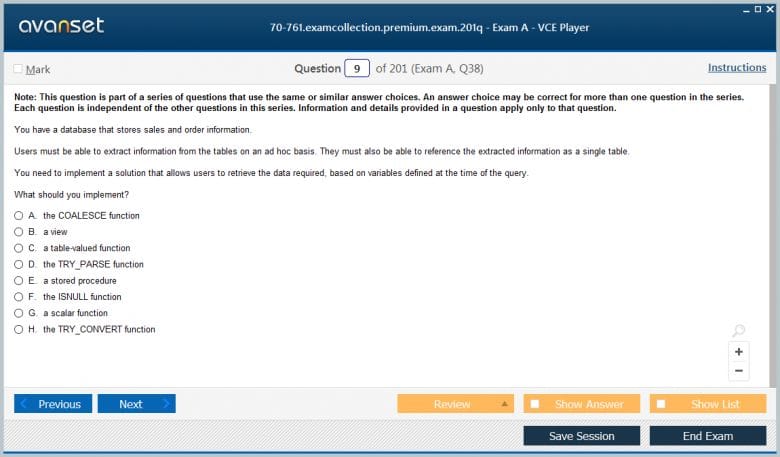
The cornerstone of querying data in T-SQL, and the most fundamental topic in the 70-761 Exam, is the SELECT statement. This statement is used to retrieve data from one or more tables. The most basic form of a query specifies the columns you want to retrieve and the table you want to retrieve them from. The syntax is straightforward: SELECT column_list FROM table_name;. This structure is the starting point for virtually every data retrieval operation you will perform.
The column_list can be a specific set of column names separated by commas. It is a best practice to always specify the exact columns you need. This makes your query more readable, reduces the amount of data transferred over the network, and makes your code less likely to break if the underlying table structure changes. For example, SELECT FirstName, LastName, EmailAddress FROM Sales.Customer; is a well-formed query that retrieves three specific pieces of information.
If you want to retrieve all columns from a table, you can use the asterisk (*) wildcard as a shorthand: SELECT * FROM Sales.Customer;. While this is convenient for ad-hoc exploration of a table's data, it should be avoided in production code for the reasons mentioned above. Relying on the wildcard can lead to performance issues and unexpected behavior when columns are added to or removed from the table.
You can also use the SELECT statement to create new, calculated columns that are not stored in the table. You can perform mathematical operations or concatenate strings to create a new column in your result set. For example, you could combine a first name and a last name into a full name. Additionally, you can assign a new name to a column in your result set using an alias with the AS keyword, such as SELECT FirstName AS FName, LastName AS LName FROM Sales.Customer;. This improves the readability of your output.
Retrieving all rows from a table is often not what you want. Typically, you are interested in a specific subset of the data. The WHERE clause is used to filter the rows returned by a query based on a specified condition. The WHERE clause follows the FROM clause and contains one or more predicates, which are expressions that evaluate to true, false, or unknown. Only the rows for which the predicate evaluates to true are included in the final result set.
The conditions in a WHERE clause are built using comparison operators. These include operators like = (equal to), <> or != (not equal to), > (greater than), < (less than), >= (greater than or equal to), and <= (less than or equal to). For example, to find all products that cost more than one hundred dollars, you would write WHERE UnitPrice > 100. The ability to write precise filter conditions was a key skill tested in the 70-761 Exam.
You can combine multiple conditions in a single WHERE clause using the logical operators AND and OR. The AND operator requires that both conditions be true for a row to be returned. The OR operator requires that at least one of the conditions be true. You can use parentheses to control the order of evaluation, just as in mathematics. For example, WHERE (Color = 'Red' OR Color = 'Blue') AND ProductStatus = 'Active'.
T-SQL provides several other useful operators for filtering. The IN operator allows you to check if a value matches any value in a list, such as WHERE Color IN ('Red', 'Blue', 'Black'). The BETWEEN operator is used to filter for a range of values, such as WHERE OrderDate BETWEEN '2025-01-01' AND '2025-01-31'. The LIKE operator is used for pattern matching in strings, using wildcards like % (matches any sequence of characters) and _ (matches any single character).
By default, a relational database does not guarantee the order in which rows will be returned by a query. If you need your results to be presented in a specific sequence, you must use the ORDER BY clause. The ORDER BY clause is typically the last clause in a SELECT statement. It allows you to sort the result set based on one or more columns, either in ascending or descending order. This is essential for creating reports and presenting data in a user-friendly way.
The basic syntax is ORDER BY column_name [ASC|DESC]. ASC specifies an ascending sort (the default if nothing is specified), and DESC specifies a descending sort. For example, to get a list of products sorted from the most expensive to the least expensive, you would use ORDER BY UnitPrice DESC. This is a fundamental concept that was regularly tested in the 70-761 Exam.
You can also sort by multiple columns. The result set is first sorted by the first column specified. Then, for any rows that have the same value in the first column, they are sorted by the second column, and so on. This allows for more granular control over the presentation of your data. For instance, ORDER BY LastName ASC, FirstName ASC would sort a list of people alphabetically by their last name, and then by their first name for people with the same last name.
The ORDER BY clause can also use aliases that you have defined in the SELECT list. This can make the code more readable, especially if the sorting is based on a calculated column. It's important to note that sorting has a performance cost, especially on large result sets, as the database engine must do extra work to arrange the data. However, for many applications, presenting data in a logical order is a critical requirement.
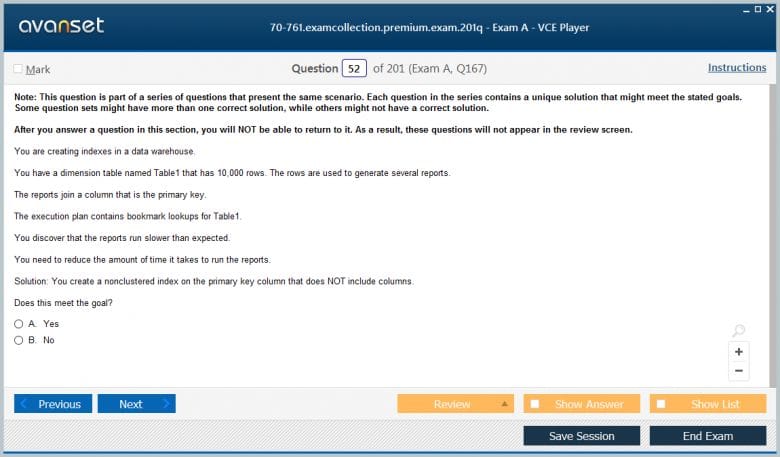
The true power of a relational database is realized when you combine data from multiple tables. This is done using a JOIN clause. A JOIN allows you to link rows from two or more tables based on a related column between them. This is the mechanism by which you "re-assemble" your normalized data to answer business questions. Mastering joins was one of the most important aspects of the 70-761 Exam. The most common type of join is the INNER JOIN.
An INNER JOIN returns only the rows where the values in the joined columns match in both tables. For example, if you join a Customers table with an Orders table on the CustomerID column, an INNER JOIN will return only the customers who have placed at least one order. Any customers who have not placed an order, and any orders that do not have a valid customer, will be excluded from the result set. The syntax involves specifying the tables and the join condition using the ON keyword.
The syntax for an inner join looks like this: SELECT c.CustomerName, o.OrderDate FROM Customers AS c INNER JOIN Orders AS o ON c.CustomerID = o.CustomerID;. Notice the use of table aliases (c and o) to make the code more concise and to specify which table each column comes from. This is a crucial best practice, especially when joining multiple tables, to avoid ambiguity.
Understanding how to correctly identify the join columns (usually the primary key in one table and the foreign key in another) is the key to writing successful joins. A single query can contain multiple JOIN clauses to bring together data from three, four, or even more tables. The ability to visualize these relationships and construct a query that accurately combines the required data is a defining skill for anyone working with T-SQL.
While the INNER JOIN is the most common way to combine tables, the 70-761 Exam required proficiency with all types of joins to handle various data retrieval scenarios. OUTER JOINs are used when you want to include rows from one table even if there are no matching rows in the other table. There are three types of outer joins: LEFT, RIGHT, and FULL. A LEFT OUTER JOIN (or simply LEFT JOIN) returns all rows from the left table and the matched rows from the right table. If there is no match, the columns from the right table will contain NULL values.
A RIGHT OUTER JOIN (or RIGHT JOIN) is the reverse. It returns all rows from the right table and the matched rows from the left table. If there is no match, the columns from the left table will be NULL. A FULL OUTER JOIN returns all rows when there is a match in either the left or the right table. It effectively combines the results of a LEFT JOIN and a RIGHT JOIN. These joins are essential for finding unmatched records, such as customers who have not placed any orders.
Another join type is the CROSS JOIN. A CROSS JOIN returns the Cartesian product of the two tables, meaning it combines every row from the first table with every row from the second table. This type of join does not have an ON clause. While it can result in a very large number of rows and should be used with caution, it is useful for specific scenarios like generating all possible combinations of items from different sets.
Finally, T-SQL allows you to join a table to itself, which is known as a SELF JOIN. This is not a distinct join type but a technique where you list the same table twice in the FROM clause, giving it two different aliases. You then join the table to itself based on a relationship between columns in that same table. This is useful for querying hierarchical data, such as finding the manager for each employee when both are stored in the same Employees table.
A very common business requirement is to summarize data. For example, you might want to find the total sales for each product category or the number of customers in each city. This is accomplished using aggregate functions in combination with the GROUP BY clause. Aggregate functions perform a calculation on a set of values and return a single value. Common aggregate functions include SUM(), COUNT(), AVG(), MIN(), and MAX().
The GROUP BY clause is used to arrange identical data into groups. When you use a GROUP BY clause, the query collapses all the rows with the same value in the specified column(s) into a single summary row. The aggregate functions in the SELECT list then operate on each of these groups. For example, SELECT ProductCategoryID, SUM(SalesAmount) AS TotalSales FROM Sales.Orders GROUP BY ProductCategoryID; would return one row for each product category, showing the total sales for that category.
A key rule when using GROUP BY, and a frequent point of confusion for beginners preparing for the 70-761 Exam, is that any non-aggregated column in the SELECT list must also be included in the GROUP BY clause. The database needs to know how to group the data to produce a single row, and it can only do so based on the columns you specify in the GROUP BY clause.
You can group by multiple columns to create more granular summaries. For instance, GROUP BY Country, City would create a group for each unique combination of country and city. The COUNT() function is particularly versatile. COUNT(*) counts all rows in a group, while COUNT(column_name) counts the non-null values in that column. COUNT(DISTINCT column_name) counts only the unique non-null values, which is useful for tasks like finding the number of distinct customers who made a purchase each month.
We have learned that the WHERE clause is used to filter individual rows before they are processed by the query. However, sometimes you need to filter the results based on the result of an aggregate function. For example, you might want to find only the product categories whose total sales are greater than ten thousand dollars. You cannot use the WHERE clause for this, because the WHERE clause is evaluated before the GROUP BY and the aggregation takes place.
This is the purpose of the HAVING clause. The HAVING clause is used to filter the groups created by the GROUP BY clause. It is evaluated after the data has been grouped and the aggregate functions have been calculated. Its syntax is similar to the WHERE clause, but the conditions in the HAVING clause can include aggregate functions. The HAVING clause always follows the GROUP BY clause in a query.
An example query would be: SELECT ProductCategoryID, SUM(SalesAmount) AS TotalSales FROM Sales.Orders GROUP BY ProductCategoryID HAVING SUM(SalesAmount) > 10000;. This query first groups all orders by their product category and calculates the total sales for each. Then, the HAVING clause filters out any of those groups where the total sales are not greater than 10,000.
It is important to remember the logical order of operations in a SELECT statement to understand the difference between WHERE and HAVING. The order is: FROM and JOINs, WHERE, GROUP BY, HAVING, SELECT, DISTINCT, and finally ORDER BY. The WHERE clause filters rows before grouping, and the HAVING clause filters groups after they are created. This distinction was a key concept for the 70-761 Exam.
T-SQL provides a rich library of built-in functions to perform operations on data. The 70-761 Exam required a solid working knowledge of the most common types of functions: scalar functions and logical functions. Scalar functions operate on a single value and return a single value. These can be categorized by the type of data they work with, such as string functions, date and time functions, mathematical functions, and conversion functions.
String functions are used to manipulate character strings. Common examples include LEN() (returns the length of a string), UPPER() and LOWER() (converts a string to uppercase or lowercase), SUBSTRING() (extracts a part of a string), and REPLACE() (replaces occurrences of a substring). These are invaluable for cleaning and formatting data for reports.
Date and time functions are essential for working with temporal data. Functions like GETDATE() return the current system date and time. DATEADD() allows you to add a specified interval (like a day or a month) to a date, while DATEDIFF() calculates the difference between two dates. YEAR(), MONTH(), and DAY() extract the respective parts of a date. These are critical for any kind of time-series analysis.
Logical functions are used to implement conditional logic within a query. The CASE expression is the most powerful of these. It allows you to return different values based on a set of conditions, similar to an IF-THEN-ELSE statement in other programming languages. The IIF() function is a simpler, shorthand version for a basic IF-THEN-ELSE condition. The CHOOSE() function returns an item from a list of values based on a specified index.
There are times when you need to combine the results of two or more separate SELECT statements into a single result set. This is accomplished using set operators. The main set operators in T-SQL are UNION, UNION ALL, INTERSECT, and EXCEPT. To use these operators, the queries being combined must have the same number of columns in their SELECT lists, and the corresponding columns must have compatible data types.
The UNION operator combines the result sets of two queries and removes any duplicate rows from the final result. For example, if you have a list of current customers and a list of former customers in separate tables, you could use UNION to get a single, consolidated list of all unique individuals who have ever been a customer.
The UNION ALL operator works similarly to UNION, but it does not remove duplicate rows. It simply concatenates the result sets of the two queries. Because it does not have the overhead of checking for and removing duplicates, UNION ALL is more performant than UNION and should be used when you know there are no duplicates or when duplicates are acceptable in the final result.
The INTERSECT operator returns only the rows that appear in both result sets. It gives you the intersection of the two queries. For example, you could use INTERSECT to find the products that were ordered in January and also ordered in February. The EXCEPT operator returns the distinct rows from the first query that are not found in the second query. For example, you could use EXCEPT to find the products that were ordered in January but were not ordered in February.
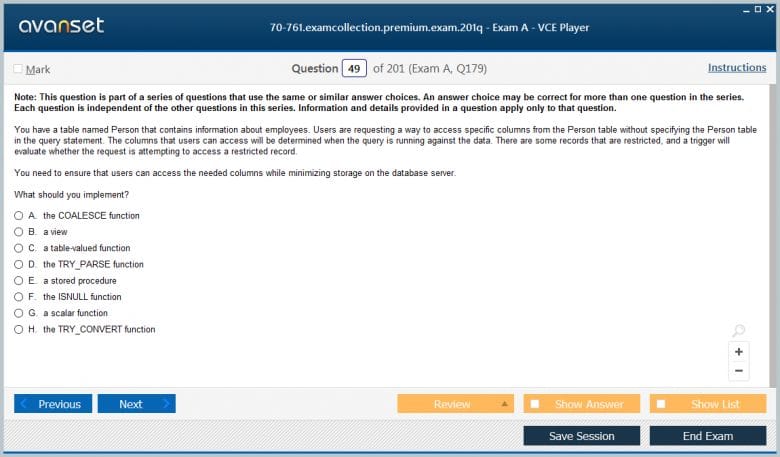
A subquery, also known as an inner query or nested query, is a SELECT statement that is nested inside another T-SQL statement, such as a SELECT, INSERT, UPDATE, or DELETE, or inside another subquery. Subqueries are a powerful tool for solving complex problems and were a significant topic in the 70-761 Exam. A subquery can be used in several places, including the SELECT list, the FROM clause, and the WHERE clause.
A common use of a subquery is in the WHERE clause for filtering. For example, to find all orders placed by customers from a specific country, you could use a subquery to first get the list of CustomerIDs from that country and then use that list to filter the Orders table. The subquery is executed first, and its result is used by the outer query. Subqueries used in this way can often be rewritten using a JOIN, and the choice between them can depend on performance and readability.
A subquery that returns a single value (a scalar value) can be used anywhere a literal value can be used, such as in the SELECT list or on one side of a comparison in the WHERE clause. A subquery that returns a list of values can be used with operators like IN or ANY.
A subquery can also be used in the FROM clause. In this case, it is often referred to as a derived table. The result set of the inner query is treated as a temporary table that the outer query can then select from. This is useful for performing multi-step transformations or aggregations on data before the final selection is made. Mastering the different types of subqueries and knowing when to use them is a key characteristic of an advanced T-SQL developer.
While a significant portion of the 70-761 Exam focused on querying data, a competent T-SQL developer must also be proficient in modifying data. The INSERT statement is used to add new rows to a table. There are two primary forms of the INSERT statement. The first form uses the VALUES clause to specify the data for a single new row. The syntax is INSERT INTO table_name (column1, column2) VALUES (value1, value2);.
It is a strong best practice to always explicitly list the columns you are inserting data into. If you omit the column list, you must provide a value for every column in the table in the exact order they appear in the table's definition. This can lead to errors if the table structure changes. By specifying the columns, you make your code more readable and resilient to schema changes.
The second form of the INSERT statement allows you to insert multiple rows from the result of a SELECT statement. The syntax is INSERT INTO table_name (column_list) SELECT_statement;. This is an extremely powerful and efficient way to copy data from one table to another or to insert summarized data into a reporting table. The columns returned by the SELECT statement must match the columns specified in the INSERT list in terms of number and data type compatibility.
When a table has an IDENTITY column, which automatically generates a sequential number for each new row, you do not need to provide a value for that column. The database engine will handle it for you. If you do need to insert an explicit value into an IDENTITY column, you must first execute the SET IDENTITY_INSERT table_name ON; command. This is generally only done for data migration or recovery scenarios.
The UPDATE statement is used to modify existing rows in a table. The basic syntax is UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;. The SET clause specifies which columns to modify and the new values they should have. The values can be literals, expressions, or the results of a scalar subquery.
The WHERE clause is critically important in an UPDATE statement. It determines which rows will be affected by the update. If you omit the WHERE clause, the UPDATE operation will be applied to every single row in the table. This is a common and potentially catastrophic mistake for new developers. It is a good practice to always write a SELECT statement with the same WHERE clause first to verify which rows will be affected before executing the UPDATE.
You can also use joins in an UPDATE statement to modify a table based on values from another table. The syntax for this can vary slightly but typically involves specifying the join in a FROM clause after the UPDATE statement. For example, you could update the UnitPrice in a Products table based on a new price list provided in a temporary staging table, joining the two tables on the ProductID.
The UPDATE statement can also modify a variable and a column in the same clause, which can be useful for certain operations like calculating a running total. Understanding how to write safe, accurate, and efficient UPDATE statements is a core competency for any database developer and was a key topic for the 70-761 Exam.
There are two primary commands for removing data from a table: DELETE and TRUNCATE. The DELETE statement is used to remove one or more rows from a table. Similar to the UPDATE statement, it uses a WHERE clause to specify which rows should be removed: DELETE FROM table_name WHERE condition;. Just as with UPDATE, omitting the WHERE clause will result in all rows being deleted from the table, so extreme caution must be exercised.
The DELETE statement is a logged operation, which means that an entry is made in the transaction log for each row that is removed. This has a few important implications. First, it can be a slow operation for a large number of rows. Second, because it is logged, a DELETE operation can be rolled back as part of a transaction. Third, it does not reset the value of an IDENTITY column. If you delete all rows and then insert a new one, the new identity value will continue from where the last one left off.
The TRUNCATE TABLE statement is used to remove all rows from a table quickly. The syntax is TRUNCATE TABLE table_name;. TRUNCATE is not a logged operation in the same way as DELETE; it deallocates the data pages used by the table and logs only the page deallocations. This makes it much faster than deleting all rows with a DELETE statement. However, it cannot be used on tables that are referenced by a foreign key constraint.
Because it is minimally logged, a TRUNCATE operation cannot be rolled back in the same way as a DELETE. It also resets the IDENTITY column back to its original seed value. The choice between DELETE and TRUNCATE was a classic scenario presented in the 70-761 Exam. DELETE should be used when you need to remove specific rows based on a condition, while TRUNCATE is for when you need to empty an entire table and performance is a key concern.
T-SQL is not just a query language; it also includes procedural programming constructs that allow you to write more complex logic, such as stored procedures, functions, and triggers. A key element of this is the ability to declare and use variables. You can declare a variable using the DECLARE keyword, specifying its name and data type (e.g., DECLARE @MyVariable INT;). You can then assign a value to it using SET or SELECT. Variables are essential for storing intermediate results and controlling program flow.
T-SQL provides control-of-flow statements to direct the execution of your code. The BEGIN...END block is used to group a set of T-SQL statements into a single logical block, similar to curly braces in other languages. The IF...ELSE statement allows you to execute different blocks of code based on a condition. For example, you could check if a certain record exists before attempting to update it.
The WHILE loop allows you to execute a block of code repeatedly as long as a specified condition is true. WHILE loops should be used with caution in T-SQL, as set-based operations (like a standard UPDATE or DELETE) are almost always more efficient than row-by-row processing in a loop. However, they are sometimes necessary for complex procedural logic. The BREAK and CONTINUE statements can be used to control the execution of the loop.
These programming constructs are the building blocks for creating stored procedures and functions. A stored procedure is a pre-compiled collection of one or more T-SQL statements that are stored on the database server. A function is a routine that can take parameters, perform an action, and return a result. A solid understanding of these procedural elements was a prerequisite for tackling the more advanced programmability topics in the 70-761 Exam.
In any programming language, robust error handling is crucial for creating reliable applications. In T-SQL, this is implemented using the TRY...CATCH construct. This is a standard structured exception handling mechanism that was a key programmability topic for the 70-761 Exam. A TRY...CATCH block allows you to wrap a set of T-SQL statements that might cause an error and then execute a separate block of code if an error occurs.
The syntax involves a BEGIN TRY...END TRY block followed immediately by a BEGIN CATCH...END CATCH block. You place your main code, such as an INSERT or UPDATE statement, inside the TRY block. If an error occurs during the execution of any statement within the TRY block, control is immediately passed to the first statement in the CATCH block. If no error occurs, the CATCH block is skipped entirely.
Inside the CATCH block, you can write code to handle the error. This might include logging the error details to an error table, sending a notification, or attempting to recover from the error. T-SQL provides several functions that can only be used inside a CATCH block to get information about the error that occurred. These include ERROR_NUMBER(), ERROR_MESSAGE(), ERROR_SEVERITY(), ERROR_STATE(), and ERROR_LINE().
Using TRY...CATCH is a best practice for any data modification statement or any complex procedure where errors are possible. It allows your code to fail gracefully instead of abruptly terminating and returning an unhandled error to the client application. You can also use the RAISERROR or THROW statements within the CATCH block to re-throw the original error or a custom error message back to the caller after you have finished your error handling logic.
A Common Table Expression, or CTE, is a temporary named result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. CTEs were introduced to improve the readability and organization of complex queries, and mastering them was an important part of preparing for the 70-761 Exam. A CTE is defined using the WITH keyword, followed by the CTE name, an optional column list, and the AS keyword with the defining query in parentheses.
CTEs can simplify queries that would otherwise require derived tables or complex subqueries. By defining a CTE at the beginning of your statement, you can break down a complex problem into logical, readable steps. You can define multiple CTEs in a single WITH clause, separating them by commas. A later CTE in the list can even reference a CTE that was defined earlier, allowing you to build up a result set in a sequential, easy-to-follow manner.
One of the most powerful features of CTEs is their ability to be used for recursive queries. A recursive CTE is one that references itself. This is the standard way in T-SQL to query hierarchical data, such as an organizational chart or a bill of materials. A recursive CTE has two parts: an anchor member, which is a query that returns the initial set of rows, and a recursive member, which is a query that references the CTE itself to return the next level of the hierarchy.
While CTEs provide a great deal of clarity, it's important to understand that they are not a performance feature in themselves. A CTE is simply a piece of syntactic sugar. The query optimizer will typically treat a query with a CTE the same way it would treat the equivalent query written with a derived table. Their primary benefit is making your T-SQL code more maintainable and understandable.
A fundamental concept in any database system, and a core knowledge area for the 70-761 Exam, is the proper use of data types. A data type defines the kind of data a column can hold, such as integer numbers, characters, or dates. Choosing the correct data type for your columns is crucial for data integrity, storage efficiency, and performance. SQL Server provides a rich set of built-in data types to cover a wide variety of needs.
Numeric data types are used for storing numbers. This category includes exact numeric types like INT (for whole numbers), BIGINT (for very large whole numbers), DECIMAL/NUMERIC (for fixed-precision decimal values, ideal for financial data), and BIT (for true/false values). It also includes approximate numeric types like FLOAT and REAL, which are used for floating-point numbers where absolute precision is not required.
Character string data types are used for storing text. The main distinction is between non-Unicode types (CHAR, VARCHAR) and Unicode types (NCHAR, NVARCHAR). Unicode types use more storage but can represent characters from virtually any language in the world. CHAR and NCHAR are fixed-length types, which can waste space if the data length varies. VARCHAR and NVARCHAR are variable-length types and are generally preferred. The MAX specifier (e.g., VARCHAR(MAX)) allows for storage of very large strings.
Other important data types include those for date and time information, such as DATE, TIME, DATETIME2 (the preferred type for combined date and time), and DATETIMEOFFSET (for time-zone-aware applications). Binary data types like BINARY and VARBINARY are used for storing raw byte data, such as image files. Understanding the appropriate use case, storage size, and behavior of each data type is a mark of a proficient T-SQL developer.
Working with string data is a daily task for most T-SQL developers, and the 70-761 Exam required proficiency with the many functions T-SQL provides for this purpose. The concatenation operator (+) is used to combine two or more strings into a single string. For more advanced concatenation and formatting, the CONCAT function (which gracefully handles NULL values) and the FORMAT function (which allows for .NET-style formatting of numbers and dates into strings) are extremely useful.
Parsing strings is another common requirement. The SUBSTRING function allows you to extract a portion of a string by specifying a starting position and a length. The LEFT and RIGHT functions are convenient shorthands for extracting characters from the beginning or end of a string. CHARINDEX and PATINDEX are used to find the starting position of a character or pattern within a string, which is often used in conjunction with SUBSTRING to extract data based on a delimiter.
Modifying strings is also a frequent necessity. The REPLACE function is used to replace all occurrences of a specific substring with another. UPPER and LOWER convert strings to their respective cases. LTRIM and RTRIM are used to remove leading and trailing spaces from a string, which is essential for data cleaning. The TRIM function is a more modern equivalent that can remove specified characters from the beginning, end, or both sides of a string.
For more complex string parsing, the STRING_SPLIT function can be a lifesaver. It takes a string and a delimiter and returns a table with a single column containing the substrings. This is an efficient way to break apart a delimited list, such as a comma-separated string of tags, into individual rows that can then be joined to other tables or processed further. Mastering these functions is key to handling real-world text data effectively.
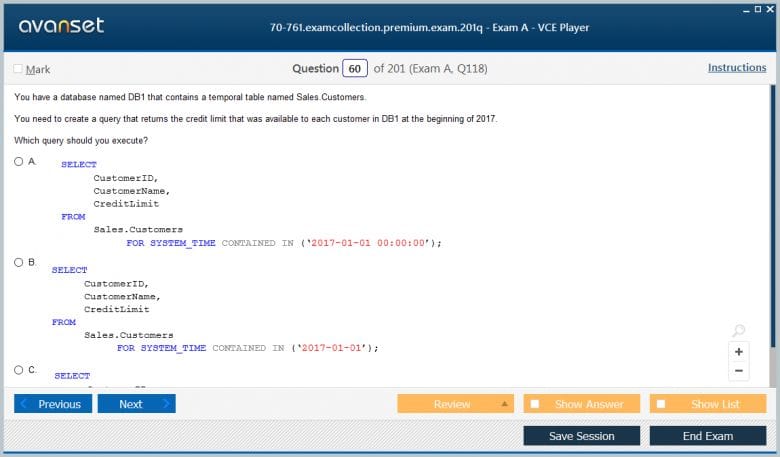
Handling temporal data correctly is a critical skill, and the 70-761 Exam tested a developer's ability to query and manipulate date and time values. T-SQL provides a powerful set of functions for this purpose. Functions like GETDATE(), SYSDATETIME(), and GETUTCDATE() are used to retrieve the current date and time from the server, with varying levels of precision and time zone awareness.
Creating date and time values from their constituent parts is often necessary. Functions like DATEFROMPARTS, TIMEFROMPARTS, and DATETIME2FROMPARTS allow you to construct a date or time value from individual integer values for the year, month, day, hour, and so on. Conversely, functions like YEAR, MONTH, DAY, and DATEPART allow you to extract specific components from an existing date and time value.
Performing calculations with dates is a very common task. The DATEDIFF function is used to calculate the amount of time (in a specified unit, like days or months) between two date and time values. The DATEADD function is used to add a specified amount of time to a date and time value, returning a new date. These two functions are the workhorses for most date-based business logic, such as calculating the age of an invoice or finding a future due date.
The EOMONTH function is a useful helper that returns the last day of the month for a given date. It can also optionally find the last day of the month for a date that is a certain number of months in the future or past. The ISDATE function can be used to check if a string is a valid date, which is useful for data validation before attempting to convert it.
SQL Server provides rich, native support for storing and querying XML data, and this was an important, advanced topic for the 70-761 Exam. XML data can be stored in a column with the XML data type. This is not just a simple text column; SQL Server parses and stores the XML in an efficient, internal binary format. This allows for validation against an XML schema and, more importantly, enables powerful querying capabilities using the XQuery language.
To query data from an XML column, you use a set of specific XML data type methods. The most common of these is the .query() method. This method takes an XQuery expression as an argument and returns a fragment of the XML as a new XML instance. This is used to extract specific sub-trees or elements from the larger XML document. For example, you could use it to retrieve the
node for a specific customer from an XML column containing their full profile.The .value() method is used to extract a single scalar value from within the XML. It takes an XQuery expression that points to a specific node or attribute and a T-SQL data type to which the result should be cast. This is the method you would use to get the text of an element, like the customer's city, and return it as a VARCHAR that can be used in the SELECT list or WHERE clause of your query.
The .exist() method is used to check for the existence of a specific node or element within the XML. It returns a BIT value: 1 if the XQuery expression returns at least one node, and 0 otherwise. This is highly efficient for use in the WHERE clause to filter rows based on the content of their XML data, for example, to find all customers who have a
Just as T-SQL provides ways to query XML data, it also provides a powerful mechanism to generate XML from relational data. This is done using the FOR XML clause, which is appended to the end of a SELECT statement. The FOR XML clause transforms the relational result set of the query into a single XML value. The 70-761 Exam required developers to know how to use this clause to shape data for use in applications or for data interchange.
There are several modes for the FOR XML clause that control the structure of the resulting XML. The FOR XML RAW mode is the simplest. It transforms each row in the result set into a generic
The FOR XML AUTO mode generates a more structured, nested XML based on the tables in the FROM clause. It creates a hierarchy where elements are named after the tables or aliases in the query. This mode is useful for generating a basic hierarchical representation of joined data with minimal effort.
The FOR XML PATH mode provides the most control and flexibility. In this mode, you can specify the structure of the XML directly in the SELECT list using XPath-like syntax. You can define element names, attribute names, and create complex nested structures by defining the path for each column. For example, SELECT CustomerID AS '@CustomerID', FirstName AS 'Name/First', LastName AS 'Name/Last' would create a nested XML structure. This mode is the most powerful for generating precisely formatted XML.
With the rise of web APIs and modern applications, JSON (JavaScript Object Notation) has become a ubiquitous data interchange format. Starting with SQL Server 2016, T-SQL includes excellent native support for storing, querying, and managing JSON data. Like with XML, you can store JSON text in a standard NVARCHAR(MAX) column, and T-SQL provides a set of functions to work with it. Understanding these functions was a key modern topic for the 70-761 Exam.
To query scalar values from a JSON string, you use the JSON_VALUE function. It takes the JSON text and a path expression (similar to XPath but for JSON) as arguments and returns a single value. For example, you could use it to extract a customer's email address from a JSON object storing their contact information. The JSON_QUERY function is similar, but it is used to extract an object or an array from the JSON string.
To parse a JSON array into a relational format, you use the OPENJSON function. OPENJSON is a table-valued function that takes a JSON string and returns a set of rows and columns. It can return a simple key-value pair representation of an object, or you can define an explicit schema using a WITH clause to map the JSON properties to strongly typed columns. This is the primary mechanism for shredding JSON data into a relational structure for storage or joining.
Just as you can query JSON, you can also generate it from relational data using the FOR JSON clause. Similar to FOR XML, you add it to the end of a SELECT statement. FOR JSON PATH generates a JSON array where each row becomes a JSON object. FOR JSON AUTO automatically creates nested JSON structures based on the tables in your query. This makes it incredibly easy to create JSON output for an API directly from your database.
Go to testing centre with ease on our mind when you use Microsoft MCSA 70-761 vce exam dumps, practice test questions and answers. Microsoft 70-761 Querying Data with Transact-SQL certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using Microsoft MCSA 70-761 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually
Microsoft 70-761 Video Course
Top Microsoft Certification Exams
Site Search:
SPECIAL OFFER: GET 10% OFF
Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.
Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
The 70-761 Dumps are Valid..I passed the 70-761 using these Dumps..Great experience
I'm planning to take this cert at Next week. Are the questions likely to change?
its update to date.
Totally Valid .. 46 Question .. my score is 900
How valid is this file?
I passed the 70-761 exam with flying colors a few weeks ago. I used 70-761 test questions and it was great. Just waiting for certification.
i cleared my 70-761 cert exam two days ago and I passed tremendously. I used VCE exam simulator to open premium files for 70-761 exam during my preparation and it was actually helpful as I passed the cert exam.
@juniour, study hard and then you can use the new updated 70-761 exam questions and answers for the cert exam and you will pass.
70-761 exam is really tough but with the assistance of 70-761 premium files from this website you don’t have to worry.
I am not happy having failed 70-761 cert exam. please advise which 70-761 practice tests should I used? Who passed already? I should do to avoid similar occurrence on the second try. thanks in advance.
i only used 70-761 practice questions available on this website in the entire preparation to the cert exam. they were realy helpful since I managed to hit the passing score. thank you so much for the questions.
I have never understood why some candidates have such a negative attitude towards exam dumps. the dumps are really good. I can confirm this because I used 70-761 braindumps and passed at the first attempt.
70-761 vce files are exactly what the candidates require to pass the exam. get them and have a chance to succeed in 70-761 cert exam.
70-761 exam questions offer the candidate with an idea of the question likely to be examined in the main exam. use these questions when preparing for the exam and you will emerge victorious when the results will be out.
@dier, 70-761 dumps are valid. I passed 70-761 exam on Tuesday using these dumps. don’t hesitate using them if you want to perform well in the cert exam.
are 70-761 exam dumps valid?