Oracle DBA Certification Exams Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate.
€134.97
Or Purchase Oracle DBA Exams Individually
| 1z0-071 | Oracle Database SQL | €69.99 | Add to cart |
| 1z0-082 | Oracle Database Administration I | €69.99 | Add to cart |
| 1z0-083 | Oracle Database Administration II | €69.99 | Add to cart |
Download Free Oracle DBA Practice Test Questions VCE Files
| Exam | Title | Files |
|---|---|---|
Exam 1z0-071 |
Title Oracle Database SQL |
Files 14 |
Exam 1z0-082 |
Title Oracle Database Administration I |
Files 4 |
Exam 1z0-083 |
Title Oracle Database Administration II |
Files 2 |
Oracle DBA Certification Exam Dumps & Practice Test Questions
Prepare with top-notch Oracle DBA certification practice test questions and answers, vce exam dumps, study guide, video training course from ExamCollection. All Oracle DBA certification exam dumps & practice test questions and answers are uploaded by users who have passed the exam themselves and formatted them into vce file format.
The journey toward becoming an Oracle Certified Database Administrator represents one of the most prestigious and lucrative career paths in the information technology sector. This comprehensive certification encompasses the mastery of database management systems, performance optimization, security implementation, and advanced troubleshooting methodologies that are essential for managing enterprise-level database infrastructures.
Oracle Database Administrator certification stands as a testament to an individual's expertise in handling complex database environments, ensuring data integrity, implementing robust security measures, and optimizing system performance across diverse organizational structures. The certification pathway demands dedication, comprehensive understanding of database architecture, and hands-on experience with real-world database scenarios.
Modern enterprises increasingly rely on sophisticated database management systems to store, process, and analyze vast amounts of critical business information. This dependency creates an unprecedented demand for skilled database administrators who can navigate the complexities of database design, implementation, maintenance, and optimization while ensuring maximum uptime and data security.
The Oracle Database Administrator certification program provides structured learning pathways that progressively build expertise from fundamental database concepts to advanced administration techniques. Candidates embarking on this certification journey will develop proficiency in database installation, configuration, backup and recovery procedures, performance tuning, security management, and comprehensive troubleshooting methodologies.
Understanding the significance of Oracle database technologies in contemporary business environments reveals why this certification commands such high regard among employers and technology professionals. Oracle databases power countless mission-critical applications across industries including finance, healthcare, retail, manufacturing, and government sectors, making certified administrators indispensable assets for organizations worldwide.
The certification process encompasses multiple examination phases, each designed to validate specific competencies and knowledge areas essential for effective database administration. From foundational SQL programming skills to advanced backup and recovery strategies, the certification pathway ensures comprehensive coverage of all critical database administration domains.
Professional database administrators who achieve Oracle certification often experience significant career advancement opportunities, increased earning potential, and enhanced job security in an increasingly competitive technology marketplace. The certification serves as a differentiating factor that demonstrates commitment to professional excellence and continuous learning in database technologies.
Entering the Oracle Database Administrator certification pathway requires careful consideration of educational background, technical prerequisites, and professional objectives. Successful candidates typically possess a strong foundation in computer science principles, understanding of operating system concepts, and familiarity with networking fundamentals that support database connectivity and performance.
Academic preparation plays a crucial role in establishing the conceptual framework necessary for advanced database administration concepts. While formal computer science education provides valuable background knowledge, many successful database administrators have transitioned from diverse academic disciplines through dedicated self-study and hands-on experience with database technologies.
Technical prerequisites encompass familiarity with command-line interfaces, basic programming concepts, and understanding of data structures and algorithms. These foundational skills enable candidates to comprehend complex database architectures, optimize query performance, and implement sophisticated backup and recovery strategies effectively.
Professional experience in information technology environments, even in roles not directly related to database administration, provides valuable context for understanding how databases integrate with broader organizational systems. Experience with system administration, network management, or software development creates advantageous background knowledge for database administration concepts.
Mathematical competency, particularly in areas of logic, statistics, and discrete mathematics, supports the analytical thinking required for database design, query optimization, and performance tuning activities. Database administrators frequently analyze performance metrics, interpret statistical data, and make data-driven decisions regarding system optimization.
Communication skills represent often-overlooked prerequisites for database administrator success. Database administrators regularly interact with development teams, business stakeholders, and executive leadership to translate technical concepts into business-relevant information and coordinate complex database initiatives across organizational boundaries.
Time management and project coordination abilities become essential as database administrators often juggle multiple concurrent responsibilities including routine maintenance tasks, emergency troubleshooting, performance optimization projects, and strategic planning initiatives that impact long-term organizational database strategies.
Oracle Database Administrator certification training programs employ systematic methodologies designed to progressively build competency from fundamental concepts to advanced administration techniques. The structured approach ensures comprehensive coverage of all essential knowledge domains while providing practical, hands-on experience with real-world database scenarios.
Classroom-based training programs offer interactive learning environments where candidates engage directly with experienced instructors, collaborate with peers, and participate in guided laboratory exercises that simulate authentic database administration challenges. These programs typically span several months and require significant time commitment to master complex concepts thoroughly.
Self-paced online training alternatives provide flexibility for working professionals who must balance certification preparation with ongoing career responsibilities. Online programs often include video lectures, interactive simulations, virtual laboratory environments, and comprehensive study materials that accommodate diverse learning preferences and schedules.
Hybrid training approaches combine the benefits of structured classroom instruction with flexible online resources, allowing candidates to participate in instructor-led sessions while accessing supplementary materials and practice exercises at their own pace. This methodology often proves most effective for candidates seeking comprehensive preparation while maintaining professional obligations.
Practical laboratory components constitute essential elements of effective database administrator training programs. Hands-on exercises provide opportunities to practice database installation procedures, configure security settings, implement backup strategies, and troubleshoot common issues in controlled environments that simulate production database systems.
Mentorship opportunities within training programs connect aspiring database administrators with experienced professionals who provide guidance, share practical insights, and offer career advice based on real-world database administration experience. These relationships often prove invaluable for understanding industry best practices and navigating complex career decisions.
Assessment methodologies throughout training programs help candidates gauge their progress, identify areas requiring additional study, and build confidence for certification examinations. Regular quizzes, practical exercises, and mock examinations provide feedback mechanisms that support effective learning and retention of critical concepts.
Structured Query Language proficiency represents the cornerstone of effective database administration, requiring deep understanding of syntax, semantics, and optimization techniques that maximize query performance while maintaining data integrity. Advanced SQL skills enable database administrators to extract meaningful insights from complex datasets, optimize application performance, and troubleshoot database-related issues effectively.
Query optimization techniques encompass understanding of execution plans, index utilization strategies, and performance tuning methodologies that dramatically improve database response times. Database administrators must master the art of analyzing query performance metrics, identifying bottlenecks, and implementing strategic optimizations that enhance overall system efficiency.
Advanced JOIN operations, subquery optimization, and complex aggregation functions require sophisticated understanding of relational algebra principles and database engine internals. These skills enable administrators to construct efficient queries that retrieve precise information while minimizing computational overhead and resource consumption.
Data manipulation language commands including INSERT, UPDATE, DELETE, and MERGE operations demand careful consideration of transaction management, concurrency control, and data consistency requirements. Database administrators must understand how these operations impact system performance and implement strategies that maintain optimal database responsiveness.
Window functions, common table expressions, and recursive query techniques represent advanced SQL capabilities that enable sophisticated data analysis and reporting functionality. Mastery of these features allows database administrators to support complex business intelligence requirements and analytical processing needs effectively.
Performance monitoring and query tuning methodologies require understanding of database statistics, execution plan analysis, and systematic optimization approaches. Database administrators must develop systematic processes for identifying performance issues, analyzing root causes, and implementing targeted solutions that address specific bottlenecks.
SQL security considerations encompass understanding of injection attack vectors, access control mechanisms, and data privacy protection strategies. Database administrators must implement robust security measures that protect sensitive information while maintaining necessary access for legitimate business operations.
Oracle database architecture encompasses sophisticated multi-layered structures including memory components, background processes, and physical storage elements that work cohesively to provide reliable, high-performance database services. Understanding these architectural components enables administrators to optimize system configurations, troubleshoot performance issues, and implement scalable database solutions.
System Global Area configuration represents a critical aspect of database performance optimization, requiring careful allocation of memory resources among shared pools, buffer caches, and other memory structures. Database administrators must understand memory management principles and implement configurations that maximize performance while avoiding resource contention issues.
Process architecture including dedicated server processes, shared server configurations, and background process management requires comprehensive understanding of how Oracle databases handle concurrent user requests and maintain system stability. Administrators must monitor process utilization and implement configurations that support optimal performance under varying workload conditions.
Physical storage management encompasses tablespace design, datafile organization, and storage optimization strategies that ensure efficient space utilization and optimal I/O performance. Database administrators must understand storage hierarchies, implement appropriate storage configurations, and monitor space utilization to prevent storage-related performance degradation.
Logical storage structures including segments, extents, and blocks require understanding of how Oracle databases organize and manage data at various granular levels. This knowledge enables administrators to implement efficient storage strategies, optimize space utilization, and troubleshoot storage-related issues effectively.
Automatic Storage Management capabilities provide simplified storage administration through automated space management, load balancing, and redundancy management features. Database administrators must understand ASM implementation strategies, configuration requirements, and operational procedures that maximize storage efficiency and reliability.
Storage performance optimization techniques encompass understanding of I/O patterns, storage subsystem design, and performance monitoring methodologies that identify and resolve storage bottlenecks. Administrators must implement storage configurations that support optimal database performance while maintaining data protection and availability requirements.
Database security represents a multifaceted discipline encompassing user authentication, authorization management, data encryption, and comprehensive audit trail implementation that protects sensitive information while supporting legitimate business operations. Database administrators must implement layered security approaches that address diverse threat vectors while maintaining system usability and performance.
User authentication mechanisms including password policies, account lockout procedures, and multi-factor authentication implementation require careful balance between security requirements and user convenience. Database administrators must configure authentication systems that provide robust security protection while supporting efficient user access to necessary database resources.
Role-based access control strategies enable granular permission management through systematic privilege assignment and inheritance hierarchies. Database administrators must design role structures that reflect organizational responsibilities, implement principle of least privilege access controls, and maintain appropriate segregation of duties across database operations.
Data encryption implementations encompass both data-at-rest and data-in-transit protection mechanisms that safeguard sensitive information from unauthorized access. Database administrators must understand encryption algorithms, key management procedures, and performance implications of various encryption strategies while ensuring compliance with regulatory requirements.
Audit trail configuration and management provide comprehensive monitoring capabilities that track database access patterns, detect suspicious activities, and support forensic investigations when security incidents occur. Database administrators must implement audit strategies that capture necessary information while minimizing performance impact and storage overhead.
Network security considerations encompass secure connection protocols, firewall configuration, and network access control mechanisms that protect database communications from interception and unauthorized access attempts. Database administrators must coordinate with network security teams to implement comprehensive protection strategies.
Vulnerability management processes require systematic identification, assessment, and remediation of security weaknesses through regular security audits, patch management procedures, and proactive threat monitoring activities. Database administrators must stay current with emerging security threats and implement appropriate countermeasures to maintain robust protection.
Comprehensive backup and recovery strategies represent critical competencies that ensure business continuity through systematic data protection, disaster recovery planning, and rapid restoration capabilities. Database administrators must master diverse backup methodologies, recovery procedures, and high availability configurations that minimize downtime and data loss risks.
Backup strategy design encompasses understanding of full backups, incremental backups, and differential backup approaches that balance data protection requirements with storage efficiency and backup window constraints. Database administrators must implement backup schedules that provide adequate protection while minimizing impact on production system performance.
Recovery Manager capabilities provide sophisticated backup and recovery automation through centralized backup management, automated backup verification, and streamlined recovery procedures. Database administrators must master RMAN configuration, backup script development, and recovery automation techniques that ensure reliable data protection and rapid restoration capabilities.
Point-in-time recovery procedures enable precise data restoration to specific moments in database history, supporting recovery from logical errors, accidental data modifications, and other scenarios requiring selective data restoration. Database administrators must understand archive log management, recovery catalog maintenance, and precise recovery timing techniques.
Disaster recovery planning encompasses comprehensive strategies for maintaining database operations during major system failures, natural disasters, and other catastrophic events. Database administrators must coordinate disaster recovery testing, maintain recovery documentation, and implement failover procedures that ensure minimal business disruption.
High availability configurations including Data Guard implementation, Real Application Clusters, and automatic failover mechanisms provide continuous database service delivery through redundancy and automated failure detection. Database administrators must understand complex clustering technologies and implement configurations that eliminate single points of failure.
Backup validation and recovery testing procedures ensure backup integrity and verify recovery capabilities through regular testing exercises that identify potential issues before actual recovery situations occur. Database administrators must implement systematic testing schedules and maintain detailed recovery documentation that supports rapid response during emergency situations.
Database performance optimization represents a sophisticated discipline requiring systematic analysis of system metrics, identification of performance bottlenecks, and implementation of targeted optimization strategies that maximize database efficiency. Database administrators must master performance monitoring tools, diagnostic methodologies, and tuning techniques that ensure optimal system responsiveness under diverse workload conditions.
Performance monitoring infrastructure encompasses comprehensive metric collection, trend analysis, and proactive alerting mechanisms that provide visibility into database performance characteristics and identify potential issues before they impact business operations. Database administrators must implement monitoring strategies that capture relevant performance data while minimizing monitoring overhead.
Query performance analysis techniques including execution plan examination, cost-based optimization understanding, and systematic query tuning methodologies enable administrators to identify and resolve query-related performance issues. This expertise requires deep understanding of database optimizer behavior, index utilization strategies, and statistical analysis techniques.
In the realm of relational database management, index design remains a cornerstone of performance engineering. An intelligently architected indexing strategy accelerates data retrieval, streamlines query execution, and dramatically reduces processing latency. However, indexes are not a universal remedy; they introduce trade-offs in terms of storage consumption and maintenance overhead. Thus, a meticulous balance must be struck between performance gain and resource cost.
Understanding the myriad types of indexes—such as B-tree, bitmap, hash, and function-based indexes—is imperative. B-tree indexes remain the default for most transactional systems due to their balanced traversal efficiency, while bitmap indexes are better suited for low-cardinality columns in decision support systems. Composite indexes, covering indexes, and filtered indexes further enhance query performance by preemptively satisfying query conditions without accessing base tables.
Optimal index placement hinges on a thorough analysis of query execution plans, workload profiles, and data distribution. Indexes should be tailored to high-frequency predicates, sorting conditions, and join keys. In environments with frequent data modifications, index fragmentation and overhead must be vigilantly monitored. Over-indexing can lead to bloated storage and degraded DML performance. Conversely, under-indexing causes excessive table scans and latency spikes.
Index maintenance strategies must include regular defragmentation routines, index rebuilding or reorganizing schedules, and usage analytics to identify obsolete structures. Partitioned indexing, partial indexing, and adaptive indexing—especially in large-scale systems—offer scalable alternatives that preserve performance without bloating the index tree. The judicious use of database advisors and query optimization hints can complement these strategies by suggesting or validating index design choices based on empirical usage patterns.
Memory management within modern databases transcends static allocation. Effective memory optimization encompasses the dynamic interplay of buffer pools, shared memory segments, and memory allocation policies—each of which plays a pivotal role in shaping overall system throughput and query responsiveness.
The buffer cache, often the largest consumer of allocated memory, must be calibrated to retain frequently accessed data blocks, thus reducing disk I/O operations. Tuning the cache hit ratio is vital—an insufficient cache size leads to frequent physical reads, while an oversized cache may starve other components. Advanced tuning incorporates buffer pool segmentation and pinning hot blocks to ensure high-velocity queries avoid disk access entirely.
The shared pool, another critical memory zone, stores parsed SQL statements, execution plans, and metadata structures. Insufficient sizing of the shared pool leads to frequent library cache misses, forcing redundant parsing operations and resource contention. Techniques such as cursor sharing, bind variable standardization, and memory reuse policies help mitigate inefficiencies within the shared pool.
Automatic memory management mechanisms provided by modern relational systems—such as dynamic memory resizing and memory advisors—must be intelligently configured. These tools analyze runtime workloads and reallocate memory across components based on real-time demands, thereby ensuring optimal utilization.
Workload-specific optimization is also paramount. OLTP systems benefit from rapid memory flushing and high concurrency handling, while OLAP environments prioritize large query memory grants and vectorized processing. Profiling memory access patterns over time, using real-time diagnostics and historical baselining, allows administrators to proactively fine-tune memory parameters and preempt bottlenecks.
Input/output subsystems represent a significant performance determinant in database environments, particularly as data volumes and transaction rates escalate. The intrinsic latency of disk access, coupled with suboptimal storage configurations, can throttle database throughput and increase response times. To achieve optimal I/O performance, administrators must combine hardware insights with software-level optimizations.
Understanding the characteristics of the storage subsystem—such as RAID configuration, SSD vs. HDD tiers, throughput limits, and latency profiles—is foundational. Each type of I/O operation (sequential read, random write, etc.) interacts differently with storage media, influencing how datafiles, redo logs, and temp segments should be distributed.
I/O pattern analysis involves studying read/write ratios, identifying hotspots, and discerning sequential versus random access patterns. Tools such as wait event diagnostics, block I/O statistics, and system-level profilers help detect inefficiencies like I/O contention or excessive redo generation.
Mitigating I/O bottlenecks often requires a multipronged approach. Implementing tablespace partitioning distributes I/O across multiple disks. Using direct-path reads, caching strategies, and asynchronous I/O can reduce physical disk dependencies. Compression techniques not only shrink storage footprints but also reduce the volume of data being read or written during query execution.
Database administrators must work closely with infrastructure teams to design tiered storage architectures, placing hot data on high-speed media and archiving cold data on economical layers. Furthermore, scheduling heavy batch jobs during low-usage windows and staggering concurrent operations can alleviate contention and maintain sustained I/O throughput.
In today’s database environments, manual performance tuning has given way to automated diagnostics and intelligent analytics. The integration of machine learning, heuristics, and historical data modeling into diagnostic frameworks empowers administrators to pinpoint and resolve issues before they impact user experience.
Automatic Workload Repository (AWR) serves as a foundational performance repository, capturing system statistics, wait events, and top SQL queries over time. This historical data enables trend analysis, workload comparison, and identification of regressions following system changes. Administrators can derive actionable insights such as CPU bottlenecks, I/O saturation points, or inefficient execution plans.
SQL Tuning Advisor augments this by offering real-time recommendations for problematic queries. These may include index suggestions, statistics refresh, SQL rewrites, or plan baselines. When integrated with SQL Plan Management, these tools preserve stable query plans and eliminate regressions caused by query optimization changes.
Systematic performance monitoring also incorporates Active Session History, real-time session tracking, and session-level waits analysis. These tools offer granular visibility into user activity, allowing performance teams to isolate high-resource sessions or deadlock-prone transactions.
Long-term performance optimization is not a one-time activity. It requires ongoing monitoring, SLA enforcement, and capacity planning. Administrators must design dashboards that surface KPIs such as query response time, concurrency metrics, transaction rates, and cache utilization. By establishing proactive thresholds and anomaly detection rules, performance degradation can be caught before it escalates into outages.
Achieving equilibrium between compute and storage subsystems is vital for sustaining peak database performance. Often, performance challenges are not rooted in a single layer but are symptomatic of imbalanced resource allocation or misaligned system components.
CPU contention, characterized by high utilization or excessive context switching, may stem from suboptimal query plans or inefficient application code. Enabling parallel execution where appropriate, minimizing function-based predicates, and using proper join algorithms are key tactics. When the compute layer is saturated, storage latency worsens, amplifying performance degradation.
On the storage side, distributing workloads across storage pools, implementing data striping, and leveraging NVMe or tiered flash arrays can significantly boost throughput. Flash cache technologies allow frequently accessed blocks to reside in ultra-low latency memory, bypassing disk altogether. Database file layout strategies—isolating redo logs, separating undo segments, and distributing temp files—contribute to smoother storage operations.
Network I/O, often overlooked, becomes critical in distributed systems or cloud-based databases. High-latency connections between application servers and the database layer can negate backend tuning efforts. Implementing packet-level compression, increasing MTU sizes, and optimizing interconnect bandwidth ensures low-latency communication across layers.
Balancing these components requires continuous feedback loops between monitoring systems, infrastructure diagnostics, and performance analytics. A holistic approach ensures that storage does not become the choke point in an otherwise well-tuned compute environment.
The modern database ecosystem is no longer a static, manually operated environment. It has evolved into a highly dynamic, intelligent landscape that demands rapid adaptability, proactive responsiveness, and continuous optimization. With digital transformation accelerating across every sector, performance engineering has transformed from reactive troubleshooting to proactive automation. Embracing automation in performance management is now not only beneficial—it is essential.
Automation in database environments empowers organizations to reduce operational friction, ensure system stability, and achieve elastic scalability. By leveraging tools capable of real-time diagnostics, autonomous tuning, and self-healing, enterprises can build highly performant systems that adapt instantly to changing workloads and infrastructure shifts. Automation does not merely replace human intervention; it enhances engineering capabilities by providing predictive intelligence and scalable governance structures.
The essence of successful automation in database performance engineering lies in orchestrating several key aspects: workload analytics, resource allocation, query optimization, parameter tuning, and environment provisioning. All these must be governed by auditability, fail-safes, and strategic oversight. When executed correctly, this architectural shift establishes a self-sustaining database ecosystem that supports both present and future enterprise demands.
The first step in intelligent automation involves implementing systems that continuously observe, learn, and adapt to workload patterns. Workload analytics tools collect high-frequency telemetry across SQL execution, wait events, memory consumption, and I/O operations. By synthesizing these metrics, systems can identify anomalous behaviors, performance regressions, and inefficient patterns that may otherwise remain hidden.
These analytics platforms often utilize machine learning algorithms to generate behavior baselines, flag outliers, and prioritize areas requiring attention. For instance, a sudden spike in I/O wait time or CPU utilization may automatically trigger a performance assessment and suggest workload redistribution or query rewriting. Over time, the platform becomes more adept at recognizing recurring patterns and automatically resolving common issues.
One of the most impactful applications is automated index recommendation and creation. By observing frequently executed queries and their filter or join predicates, the system can proactively create composite or filtered indexes that improve query performance without manual analysis. Similarly, query plans can be auto-tuned by binding stable execution plans to queries, thereby avoiding plan regression.
Another powerful use case lies in auto-tiering storage solutions. Based on data access frequency and volatility, automation platforms can dynamically migrate datasets between high-speed flash storage and cost-effective archival storage. This ensures optimal performance while minimizing unnecessary storage expenditures.
These analytics-driven insights empower database administrators (DBAs) to transition from firefighting roles to strategic oversight, focusing on high-level governance, design patterns, and business alignment.
Every database engine is controlled by hundreds of tunable parameters that influence memory allocation, connection concurrency, parallel execution, cache behavior, and more. Manually tuning these parameters is a time-consuming and error-prone process, especially in environments with fluctuating workload patterns and heterogeneous applications.
Automated parameter tuning systems bridge this gap by continuously evaluating how parameter changes affect performance metrics. These systems apply controlled adjustments—such as resizing buffer pools, adjusting maximum memory grants, or reallocating shared memory segments—and measure the downstream impact on transaction throughput, query latency, and system stability.
Dynamic resource governance is especially critical in multitenant and containerized architectures where resource competition can cause unpredictable spikes or throttling. Automated tuning helps maintain equilibrium by redistributing compute and memory resources in real time based on tenant behavior, query complexity, and time-of-day utilization trends.
Additionally, concurrency-related parameters such as connection pool size, redo log buffer size, and background writer thresholds can be dynamically tuned to match current transaction loads. This prevents bottlenecks during high-volume windows such as month-end processing or seasonal spikes, while conserving resources during low-demand periods.
All changes made by automated systems must be logged, auditable, and, if necessary, reversible. Rollback capabilities are essential for maintaining control, especially in environments governed by strict change management policies or compliance frameworks.
Query performance remains at the heart of database optimization. Even with efficient schema design and indexing strategies, suboptimal SQL queries can consume disproportionate system resources and degrade user experience. Automated query optimization tools leverage execution statistics, plan histories, and query profiling data to identify inefficiencies and recommend precise improvements.
One key capability is real-time query rewrites. Systems can suggest or implement transformations—such as changing correlated subqueries to joins, unnesting nested queries, or rewriting EXISTS clauses—that significantly enhance execution speed. For OLAP workloads, automation platforms can determine when to materialize intermediate results or apply result caching for frequently repeated analytic queries.
Execution plan management is another crucial automation frontier. Plan stability is vital for predictable performance. Platforms can detect when plan changes occur due to statistics updates, environment changes, or optimizer decisions. They can then freeze known-good plans or guide the optimizer using plan baselines, hints, or SQL profiles.
Automated SQL tuning advisors also provide what-if analysis—showing the expected impact of recommended changes without executing them. This empowers DBAs and developers to make informed decisions and validate performance improvements in controlled environments before promoting them to production.
By integrating query optimization into the automation workflow, organizations can maintain consistent performance across rapidly evolving applications and diverse user workloads.
The principles of DevOps have transformed database administration by introducing infrastructure as code (IaC) into database lifecycle management. Through declarative provisioning, entire database environments can be instantiated, scaled, modified, or retired using scripted templates. This drastically reduces provisioning time, enhances reproducibility, and ensures configuration standardization.
Using configuration management tools, database clusters can be defined as templates that include OS-level parameters, database initialization settings, storage layout, user privileges, and network configurations. These templates are version-controlled, enabling traceable deployments, rollbacks, and environment cloning.
IaC also plays a pivotal role in performance engineering. Performance test environments can be spun up on-demand with precise resource configurations, synthetic workloads, and real-world datasets. After testing, these environments can be retired automatically, optimizing infrastructure utilization and cost efficiency.
In hybrid or multi-cloud architectures, IaC facilitates deployment across heterogeneous platforms while maintaining consistent performance characteristics. Auto-scaling groups, parameterized instance sizes, and built-in monitoring hooks ensure that environments remain elastic and observable.
Declarative orchestration also aligns with continuous integration/continuous deployment (CI/CD) pipelines, allowing performance validation and database tuning to become part of the automated release process. This ensures that each application release is accompanied by an optimized and resilient database backend.
Modern data infrastructures increasingly rely on intelligent autonomy—systems that not only detect anomalies but also rectify them instantaneously without human intercession. This orchestration marries continuous vigilance, anomaly discernment, and responsive script execution, forging a self‑regulating ecosystem. Imagine a scenario: as storage consumption nears critical mass, the system engages archival processes, compresses archival‑age partitions, or dynamically enlarges storage capacity. When a protracted query triggers session constraint or surges CPU usage, the framework performs judicious termination or channels workloads to less encumbered nodes. Such capabilities signify a paradigm shift from reactive firefighting to consummate self‑governance.
Self‑remediation reaches beyond mere error correction—it encompasses service revivals, cache rejuvenation, index refinement, and orchestrated rerouting in clustered architectures. In high‑availability ensembles, automated redirection, failover enactment, or node redistribution becomes second nature. Predictive remediation enriches this by interpreting historical trajectories and live indicators to forestall emergent bottlenecks. For instance, noticing a gradual stupendous uptick in redo log volumes could presage transactional log saturation; the system might accordingly amplify buffer thresholds or alert administrators well before latencies manifest.
At the heart of this self‑healing regime is unceasing oversight—fine‑grained metrics, sentinel probes, latency graphs, and workload diagnostics feed into an analytical substrate. Rather than superficial thresholds, anomalies are discerned via contextual baselines, dynamic thresholds, and statistical variance analysis. Unusual CPU patterns, atypical I/O latency, thread pile‑ups, or erratic cache miss ratios trigger inference engines.
To transcend superficial alarms, these systems frequently incorporate unsupervised machine learning techniques—clustering, isolation forests, or density‑based sensitivity analysis—to spotlight outliers and emergent trends. The scripting layer then internalizes these insights, mapping them to calibrated remediation routines. This synthesis enables swift resolution of incipient dysfunction before cascading failure ensues.
Upon detection, the self‑healing layer deploys remedial stratagems:
Storage optimization: archival of dormant logs, compression of under‑utilized partitions, auto‑scaling of storage provisioning.
Query governance: termination of runaway sessions, regimentation of resource concurrency, load redistribution to alleviate hotspots.
Service restoration: micro‑restarts of errant services, cache invalidation and refresh, index reorganization to rejuvenate performance.
Cluster orchestration: rerouting client sessions away from impaired nodes, initiating failover to standby clusters, rebalancing shards to ensure distribution equity.
Each intervention is predicated upon validation logic—verifying that the detected anomaly is not a transient blip or controlled maintenance event—thereby warding off false positives and superfluous disruptions.
Elevating the paradigm, predictive remediation leverages time‑series analysis and trend extrapolation. Rather than waiting for thresholds to breach, the system extrapolates trajectories—a slow but steady rise in transaction redo log throughput, for instance, may signal impending saturation. The automation responds proactively: increasing buffer capacities, preemptively archiving logs, or dispatching advisories to administrators to avert impending latency spikes.
This anticipatory posture reduces firefighting, preserves performance integrity, and fosters resilience—especially in environments subject to fluctuating workloads, seasonal data surges, or batch processing rhythms.
While autonomy is powerful, it must be circumscribed—each script or remediation module includes built‑in validation heuristics. These checks ensure that actions are applied only when contextual criteria align: e.g., disk free space falls below a defined percentile, I/O latency sustains elevated status for a calibrated duration, or CPU load remains above a threshold across multiple intervals.
Equally critical is the notion of "safe mode"—a preparatory phase where proposed changes can be previewed or dry‑run in simulation, allowing confirmation of impact without actual execution. This prevails as a risk‑mitigation tactic, enabling administrators to vet remedies, ensure idempotency, and prevent deleterious side‑effects. Once verified, full execution may proceed—or human override can intercede if anomalous conditions persist.
In the evolving landscape of technical discourse, especially when describing intricate systems like self-remediating architectures, the choice of language plays a pivotal role in conveying depth, precision, and sophistication. Employing an uncommon yet precise lexicon not only elevates the narrative but also facilitates a clearer understanding of abstract or complex concepts. The integration of such terminology serves as more than ornamental prose; it acts as a bridge between conceptual frameworks and their practical implementations, encapsulating multifaceted ideas into memorable and articulate expressions.
Rare and specialized vocabulary enriches technical documentation by allowing authors to capture nuances that conventional terms often dilute or oversimplify. For example, in describing system behavior, words like “autognostic” vividly depict the self-aware nature of an architecture that continuously monitors and evaluates its own operational state. This contrasts with more generic descriptors such as “self-monitoring” which may fail to evoke the system's depth of introspection and adaptive capability. Using such lexicon positions the narrative at a higher plane, inviting readers to appreciate the layered complexities embedded within.
Systems engineering and digital infrastructure design often wrestle with phenomena that resist easy quantification or simplistic characterization. Terms such as “nebulous drift” elegantly express the insidious, gradual changes in system performance or behavior that evade rigid detection thresholds. Unlike overt failures or sudden breakdowns, nebulous drift represents the slow erosion of optimal states—akin to a digital entropy creeping beneath the operational surface. By articulating this phenomenon with rare vocabulary, the narrative captures a sense of subtlety and urgency that generic terminology might miss.
Similarly, “transient resonance” describes fleeting yet repetitive instabilities within a system—momentary oscillations that may portend larger systemic disruptions if left unchecked. This term conjures an image of ephemeral waves of discord passing through an otherwise steady state, inviting engineers to look beyond isolated metrics towards temporal patterns and correlations. The use of such vocabulary enhances the reader's conceptual grasp by linking technical observations with evocative metaphorical imagery.
The refinement of automated systems hinges on adaptive feedback mechanisms, which demand terms that convey both methodological rigor and flexibility. “Heuristic calibration” denotes the iterative tuning of detection and response rules based on empirical learning rather than fixed prescriptions. It acknowledges that thresholds and triggers evolve in response to environmental changes, workload variations, and observed efficacy. This term encapsulates the continuous learning ethos underpinning modern self-remediating architectures, emphasizing the dynamic interplay between data-driven insight and operational policy.
Meanwhile, “idempotent remediation” captures a critical property of resilient automation workflows—the ability to safely repeat an intervention without adverse side effects. In practice, this ensures that remedial actions such as restarting a service, reallocating resources, or rebalancing workloads can be invoked multiple times, either due to cascading alerts or execution retries, without compounding errors or introducing instability. Using this term highlights an essential design principle that underwrites system robustness and reliability.
Beyond reactive responses, sophisticated self-healing systems engage in “prophylactic orchestration,” a preemptive choreography of mitigation steps designed to forestall degradation. This concept moves the narrative from recovery to anticipation, illustrating how systems leverage predictive analytics, anomaly forecasting, and contextual awareness to initiate automated defenses before faults manifest. The term “prophylactic” borrowed from medical lexicon, enriches the technological discourse by implying a strategic, preventive posture that goes beyond mere troubleshooting.
By integrating prophylactic orchestration into architectural descriptions, authors underscore the shift from traditional incident management toward continuous, intelligent risk mitigation. This lexical choice aligns the narrative with modern trends in autonomous system design, such as predictive maintenance, adaptive scaling, and dynamic resource provisioning.
The notion of a “cognitive sabbatical” introduces an intriguing dimension to automation—the deliberate suspension or delay of action to allow deeper contextual analysis or human validation. This term, rare in technology literature, metaphorically represents a pause akin to a mental retreat where a system refrains from immediate intervention to avoid premature or erroneous remediation. Cognitive sabbaticals are crucial in complex environments where hasty automation could exacerbate issues or disrupt dependent processes.
Incorporating this term into discussions about autonomous systems enhances the narrative’s sophistication by recognizing the limits of algorithmic certainty and the value of reflective judgment. It suggests that advanced architectures combine rapid reaction with thoughtful restraint, balancing speed with prudence.
Complex infrastructures frequently encounter situations where simultaneous but opposing effects unfold—a phenomenon aptly described as “antipode convergence.” This term captures the idea of failover symmetry or counteracting system responses that may appear paradoxical but are inherently linked. For example, scaling up resources to resolve latency could trigger cache invalidations that temporarily degrade performance elsewhere, creating a duality of improvement and deterioration.
By naming this intricate interplay, the narrative gains a powerful tool for explaining the unintended consequences and systemic tensions that arise in distributed environments. Antipode convergence highlights the necessity for holistic, context-aware orchestration strategies that account for multifaceted impacts rather than isolated fixes.
In the intricate world of advanced system design and automated frameworks, the way we communicate concepts profoundly impacts understanding and implementation. Integrating a rarefied lexicon into technical writing serves not merely as stylistic embellishment but as a fundamental enhancer of clarity and precision. Terms like autognostic, nebulous drift, heuristic calibration, and idempotent remediation encapsulate sophisticated concepts that ordinary language struggles to convey succinctly. This linguistic precision provides a double benefit: it sharpens the conceptual focus while simultaneously elevating the discourse to match the complexity of the subject matter.
The strategic use of rare vocabulary acts as a cognitive scaffold for readers, enabling them to internalize complex ideas with greater ease. For example, describing a system as autognostic implies a level of self-awareness and intrinsic feedback that goes far beyond basic monitoring or alerting. This not only clarifies the system's capabilities but invites a deeper engagement with its adaptive processes. Such nuanced language bridges the gap between abstract theory and practical engineering, fostering a richer, more actionable comprehension.
One of the foremost challenges in articulating the behavior of self-remediating or autonomous systems lies in capturing subtle dynamics and multi-layered interactions. Common technical jargon often falls short when addressing phenomena such as slow degradation, fleeting instabilities, or iterative fine-tuning. Introducing terms such as nebulous drift addresses this gap by vividly describing gradual, hard-to-detect shifts that erode system performance over time. This term encourages engineers to look beyond immediate alarms and consider long-term systemic entropy that may otherwise remain obscured.
Similarly, transient resonance describes momentary oscillations or fluctuations that repeat and may signal underlying issues. Unlike simplistic fault descriptions, this term conveys the notion of recurring but non-persistent instability, emphasizing temporal patterns rather than isolated events. By adopting such vocabulary, technical communicators equip their audiences with a lexicon tailored for nuanced observation and diagnosis, ultimately improving problem identification and resolution efficacy.
Modern self-healing frameworks rely heavily on continuous learning and adaptation, necessitating vocabulary that reflects this dynamic process. Heuristic calibration exemplifies this concept by denoting the iterative adjustment of detection thresholds and response protocols based on empirical evidence rather than static rules. This linguistic choice foregrounds the importance of experiential learning and flexibility, acknowledging that rigid, one-size-fits-all configurations are inadequate in fluid operational contexts.
Employing heuristic calibration in technical discourse helps frame automation not as a set of predetermined reactions but as a living process—one that evolves through feedback loops, pattern recognition, and predictive modeling. This perspective encourages practitioners to design systems with built-in elasticity, capable of refining themselves in response to shifting environmental conditions and emerging threat landscapes.
In highly automated environments, remediation actions must be designed with fail-safety in mind. The concept of idempotent remediation is critical here: it refers to the property of remedial operations that can be executed repeatedly without causing unintended side effects. This ensures that automated fixes, whether they involve resource reallocation, service restarts, or configuration resets, do not compound problems or introduce new faults.
By integrating the term idempotent remediation into the technical vocabulary, communicators highlight a foundational principle of resilient automation. It signals to engineers and stakeholders alike that interventions are robust, repeatable, and designed for minimal risk, fostering trust in autonomous systems and their decision-making capabilities.
The proactive nature of advanced self-remediating architectures can be succinctly captured through the notion of prophylactic orchestration. Borrowed from medical terminology, prophylactic orchestration describes the anticipatory coordination of automated workflows intended to prevent system degradation before it manifests as failure. This contrasts with traditional reactive paradigms and aligns with modern imperatives of predictive maintenance and continuous availability.
Incorporating prophylactic orchestration into technical descriptions elevates the conversation beyond basic fault remediation to strategic resilience planning. It encourages organizations to adopt a mindset that prioritizes foresight, leveraging predictive analytics, anomaly detection, and contextual awareness to intervene early and minimize operational risk. This concept is particularly valuable in distributed, cloud-native, or hybrid environments where system complexity demands proactive governance.
While automation accelerates incident response and operational efficiency, indiscriminate or premature actions can exacerbate problems. The idea of a cognitive sabbatical introduces a nuanced dimension to automated workflows by representing a purposeful pause or delay intended for deeper contextual analysis or human intervention. This intentional withholding of immediate action acknowledges the limitations of algorithmic certainty and the necessity for validation in complex scenarios.
Using cognitive sabbatical as part of a system's lexicon underscores a sophisticated approach to automation—one that blends rapid response with thoughtful restraint. It communicates the design philosophy of balancing agility with accuracy, ensuring that automated processes do not undermine system stability or user trust through rash decisions.
Complex infrastructures often encounter phenomena where simultaneous, opposing system reactions unfold—phenomena that can be described as antipode convergence. This term encapsulates situations such as failover symmetry or the interplay of countervailing forces that challenge simplistic resolution models. For instance, scaling operations intended to improve performance may inadvertently trigger cache invalidations, causing temporary degradations elsewhere.
Antipode convergence enriches the narrative by acknowledging the multifaceted nature of systemic interactions and the intricacies of orchestration within distributed systems. It highlights the necessity of holistic design philosophies and orchestration frameworks that consider collateral impacts and strive for equilibrium rather than isolated optimization.
The deliberate inclusion of rare and precise vocabulary in technical communication fosters multiple strategic advantages. Primarily, it sharpens conceptual clarity by condensing complex ideas into singular terms that carry rich semantic weight. This reduction of ambiguity facilitates shared understanding and expedites collaborative problem-solving. Furthermore, such language cultivates cognitive resonance, enabling audiences to form vivid mental models that enhance retention and application of knowledge.
From a professional standpoint, mastery of this lexicon conveys subject-matter expertise and elevates credibility, positioning authors as thought leaders capable of articulating sophisticated concepts with clarity and finesse. This is particularly important when engaging diverse stakeholders—engineers, architects, executives, and auditors—who benefit from precise and nuanced communication tailored to their decision-making contexts.
Additionally, the use of rare vocabulary mirrors the evolving nature of the systems themselves. Just as self-remediating architectures embody continuous learning, adaptability, and contextual responsiveness, the language used to describe them must be equally dynamic and expressive. This linguistic alignment enhances the synergy between technological innovation and strategic narrative, ensuring that communication effectively supports operational excellence and strategic foresight.
In conclusion, integrating a refined lexicon into discussions about advanced automated systems transforms technical writing from a procedural recounting into a compelling narrative. It empowers organizations to not only document but also conceptualize, trust, and innovate their complex infrastructures with confidence and clarity. As technology continues to evolve, so too must the language we use—embracing precision, rarity, and depth to illuminate the path toward resilient, intelligent automation.
ExamCollection provides the complete prep materials in vce files format which include Oracle DBA certification exam dumps, practice test questions and answers, video training course and study guide which help the exam candidates to pass the exams quickly. Fast updates to Oracle DBA certification exam dumps, practice test questions and accurate answers vce verified by industry experts are taken from the latest pool of questions.
Oracle Oracle DBA Video Courses
Top Oracle Certification Exams
Site Search:
SPECIAL OFFER: GET 10% OFF
Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.
Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
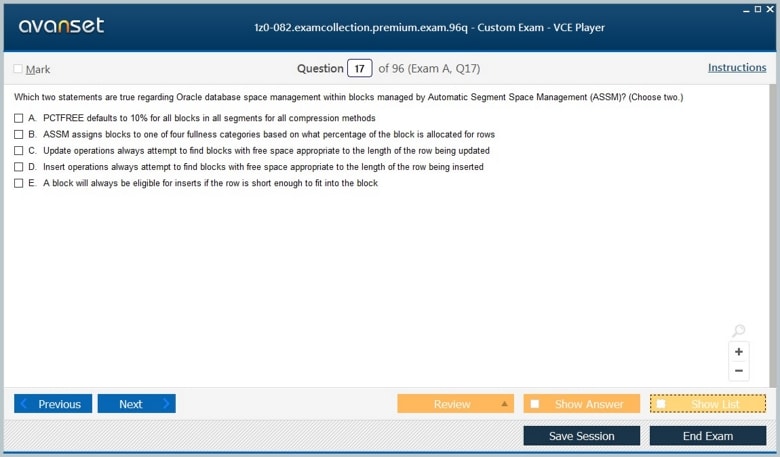
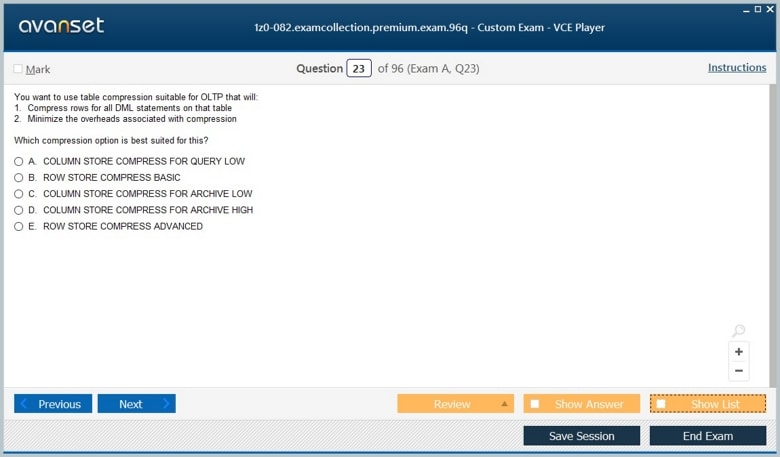
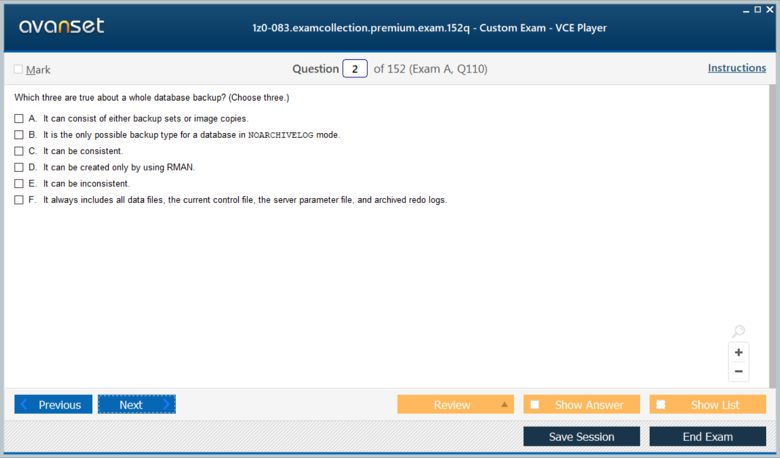
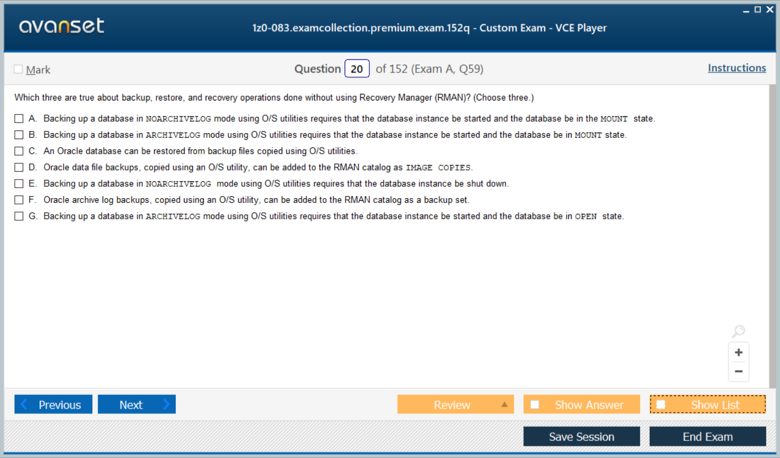
Any one who passed Oracle 12c DBA exam in 2019
@reuben, the oracle dba exam dumps are very crucial to certiifcation....they are valid about 75-80% implying that you av already exceeded the oracle passmark
hello? i need someone to confirm the validity of oracle dba braindumps....anyone???
wow!! i have finally got certified ladies and gentlemen....the secret is geting familiar with oracle dba exam questions
@ptoryo, the exacollection.com is the home of the best ....you cant fail your exam with the several oracle dba braindump that are available here
@kiposut, the most important thing is to check the validity of the materials you are using.....some oracle dba prep materials are very invalid....you might have used the invalid materials then
wow! this is the best site ever....i have just found the oracle dba vce files...i have been looking for....more so,the free vce player demo. thanks to this site....it eased my revision process
i did the exam and there was hardly any similar question from the oracle dba practice test i used....i am now worried i dont think i will pass
suppose you have come across any invalid oracle dba dump.....plz let us know as we are doing a thorough revision for the coming exam
what is the secret of passing oracle dba exams....i have failed one and currently preparing for a retake
database is becoming the key thing in every field today...it is necessary to get the oracle dba certification in order to remain relevant in this massively growing industry